
ساختن مدل تحلیل احساسات خود ممکن است دلهره آور به نظر برسد. این راهنما شما را از طریق مراحل شروع به کار راهنمایی می کند.
تحلیل احساسات یک تکنیک پردازش زبان طبیعی (NLP) است که نگرش پشت یک متن را شناسایی می کند. به آن عقیده کاوی نیز می گویند. هدف تجزیه و تحلیل احساسات این است که مشخص شود آیا یک متن خاص دارای احساسات مثبت، منفی یا خنثی است. این به طور گسترده توسط مشاغل برای طبقه بندی خودکار احساسات در نظرات مشتریان استفاده می شود. تجزیه و تحلیل حجم زیادی از بررسی ها به دستیابی به بینش ارزشمندی در مورد ترجیحات مشتریان کمک می کند.
تنظیم محیط
برای پیگیری باید با اصول پایتون آشنا باشید. به Google Colab بروید یا Jupyter Notebook را باز کنید. سپس یک نوت بوک جدید بسازید. دستور زیر را برای نصب کتابخانه های مورد نیاز در محیط خود اجرا کنید.
کد منبع کامل این پروژه در این مخزن GitHub موجود است.
! pip install tensorflow scikit-learn pandas numpy pickle5
شما از NumPy و کتابخانه pandas برای دستکاری مجموعه داده استفاده خواهید کرد. TensorFlow برای ایجاد و آموزش مدل یادگیری ماشین. Scikit-Learn برای تقسیم مجموعه داده به مجموعه های آموزشی و آزمایشی. در نهایت، از pickle5 برای سریال سازی و ذخیره شی توکنیزر استفاده خواهید کرد.
واردات کتابخانه های مورد نیاز
کتابخانه های لازم را وارد کنید که از آنها برای پیش پردازش داده ها و ایجاد مدل استفاده خواهید کرد.
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense, Dropout
import pickle5 as pickle
از کلاس هایی که از ماژول ها وارد می کنید بعداً در کد استفاده خواهید کرد.
در حال بارگیری مجموعه داده
در اینجا، از مجموعه داده Trip Advisor Hotel Reviews از Kaggle برای ساخت مدل تحلیل احساسات استفاده خواهید کرد.
df = pd.read_csv('/content/tripadvisor_hotel_reviews.csv')
print(df.head())
مجموعه داده را بارگیری کنید و پنج ردیف اول آن را چاپ کنید. چاپ پنج سطر اول به شما کمک می کند نام ستون های مجموعه داده خود را بررسی کنید. این در هنگام پیش پردازش مجموعه داده بسیار مهم خواهد بود.

مجموعه داده Trip Advisor Hotel Reviews دارای یک ستون فهرست، یک ستون بررسی و یک ستون رتبه بندی است.
پیش پردازش داده ها
ستون های بررسی و رتبه بندی را از مجموعه داده انتخاب کنید. یک ستون جدید بر اساس ستون Rating ایجاد کنید و نام آن را احساس کنید. اگر امتیاز بیشتر از 3 است، احساسات را مثبت علامت بزنید. اگر امتیاز کمتر از 3 است، آن را منفی بنویسید. اگر امتیاز دقیقاً 3 است، آن را خنثی علامت بزنید.
فقط ستون های بررسی و احساس را از مجموعه داده انتخاب کنید. سطرها را به طور تصادفی با هم مخلوط کنید و شاخص قاب داده را بازنشانی کنید. مخلوط کردن و تنظیم مجدد اطمینان حاصل می کند که داده ها به طور تصادفی توزیع می شوند، که برای آموزش و آزمایش مناسب مدل ضروری است.
df = df[['Review', 'Rating']]
df['sentiment'] = df['Rating'].apply(lambda x: 'positive' if x > 3
else 'negative' if x < 3
else 'neutral')
df = df[['Review', 'sentiment']]
df = df.sample(frac=1).reset_index(drop=True)
متن Review را با استفاده از توکنایزر به دنباله ای از اعداد صحیح تبدیل کنید. این یک فرهنگ لغت از کلمات منحصر به فرد موجود در متن Review ایجاد می کند و هر کلمه را به یک مقدار صحیح منحصر به فرد نگاشت می کند. از تابع pad_sequences از Keras استفاده کنید تا مطمئن شوید که تمام دنبالههای بررسی دارای طول یکسان هستند.
tokenizer = Tokenizer(num_words=5000, oov_token='<OOV>')
tokenizer.fit_on_texts(df['Review'])
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(df['Review'])
padded_sequences = pad_sequences(sequences, maxlen=100, truncating='post')
برچسبهای احساسات را به رمزگذاری One-hot تبدیل کنید.
sentiment_labels = pd.get_dummies(df['sentiment']).values
رمزگذاری تک داغ دادههای دستهبندی را در قالبی نشان میدهد که کار کردن با مدلهای شما آسانتر است.
تقسیم مجموعه داده ها به مجموعه های آموزشی و آزمایشی
از scikit-learn برای تقسیم تصادفی مجموعه داده به مجموعه های آموزشی و آزمایشی استفاده کنید. شما از مجموعه آموزشی برای آموزش مدل برای طبقه بندی احساسات نظرات استفاده خواهید کرد. و شما از مجموعه تست برای دسترسی به میزان خوبی که مدل در طبقه بندی بررسی های جدید دیده نشده است استفاده خواهید کرد.
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, sentiment_labels, test_size=0.2)
اندازه تقسیم مجموعه داده 0.2 است. این به این معنی است که 80٪ از داده ها مدل را آموزش می دهند. و بقیه 20 درصد عملکرد مدل را آزمایش خواهند کرد.
ایجاد شبکه عصبی
یک شبکه عصبی با شش لایه ایجاد کنید.
model = Sequential()
model.add(Embedding(5000, 100, input_length=100))
model.add(Conv1D(64, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
اولین لایه شبکه عصبی یک لایه Embedding است. این لایه نمایش متراکم کلمات را در واژگان می آموزد. لایه دوم یک لایه Conv1D با 64 فیلتر و اندازه هسته 5 است. این لایه با استفاده از یک پنجره کشویی کوچک به اندازه 5 عملیات کانولوشن را روی توالی های ورودی انجام می دهد.
لایه سوم توالی نقشه های ویژگی را به یک بردار کاهش می دهد. حداکثر مقدار را روی نقشه هر ویژگی می گیرد. لایه چهارم یک تبدیل خطی روی بردار ورودی انجام می دهد. لایه پنجم به طور تصادفی کسری از واحدهای ورودی را در حین آموزش روی 0 قرار می دهد. این به جلوگیری از بیش از حد مناسب کمک می کند. لایه نهایی خروجی را به یک توزیع احتمال در سه کلاس ممکن تبدیل می کند: مثبت، خنثی و منفی.
آموزش شبکه عصبی
مجموعه های آموزشی و آزمایشی را با مدل مطابقت دهید. الگو را برای ده دوره آموزش دهید. می توانید تعداد دوره ها را به دلخواه تغییر دهید.
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_test, y_test))
پس از هر دوره، عملکرد مدل در مجموعه آزمایش ارزیابی می شود.
ارزیابی عملکرد مدل آموزش دیده
از متد model.predict() برای پیشبینی برچسبهای احساسات مجموعه تست استفاده کنید. امتیاز دقت را با استفاده از تابع accuracy_score() از scikit-learn محاسبه کنید.
y_pred = np.argmax(model.predict(x_test), axis=-1)
print("Accuracy:", accuracy_score(np.argmax(y_test, axis=-1), y_pred))
دقت این مدل حدود 84 درصد است.
ذخیره مدل
مدل را با استفاده از متد model.save() ذخیره کنید. از pickle برای سریال سازی و ذخیره شی توکن ساز استفاده کنید.
model.save('sentiment_analysis_model.h5')
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
شی توکن ساز متن ورودی شما را نشانه گذاری می کند و آن را برای تغذیه به مدل آموزش دیده آماده می کند.
استفاده از مدل برای طبقه بندی احساس متن خود
پس از ایجاد و ذخیره مدل، می توانید از آن برای طبقه بندی احساس متن خود استفاده کنید. ابتدا مدل ذخیره شده و توکنایزر را بارگیری کنید.
# Load the saved model and tokenizer
import keras
model = keras.models.load_model('sentiment_analysis_model.h5')
with open('tokenizer.pickle', 'rb') as handle:
tokenizer = pickle.load(handle)
تابعی را برای پیش بینی احساس متن ورودی تعریف کنید.
def predict_sentiment(text):
# Tokenize and pad the input text
text_sequence = tokenizer.texts_to_sequences([text])
text_sequence = pad_sequences(text_sequence, maxlen=100)
# Make a prediction using the trained model
predicted_rating = model.predict(text_sequence)[0]
if np.argmax(predicted_rating) == 0:
return 'Negative'
elif np.argmax(predicted_rating) == 1:
return 'Neutral'
else:
return 'Positive'
در نهایت متن خود را پیش بینی کنید.
text_input = "I absolutely loved my stay at that hotel. The staff was amazing and the room was fantastic!"
predicted_sentiment = predict_sentiment(text_input)
print(predicted_sentiment)
احساس پیش بینی شده در بررسی فوق به شرح زیر است:
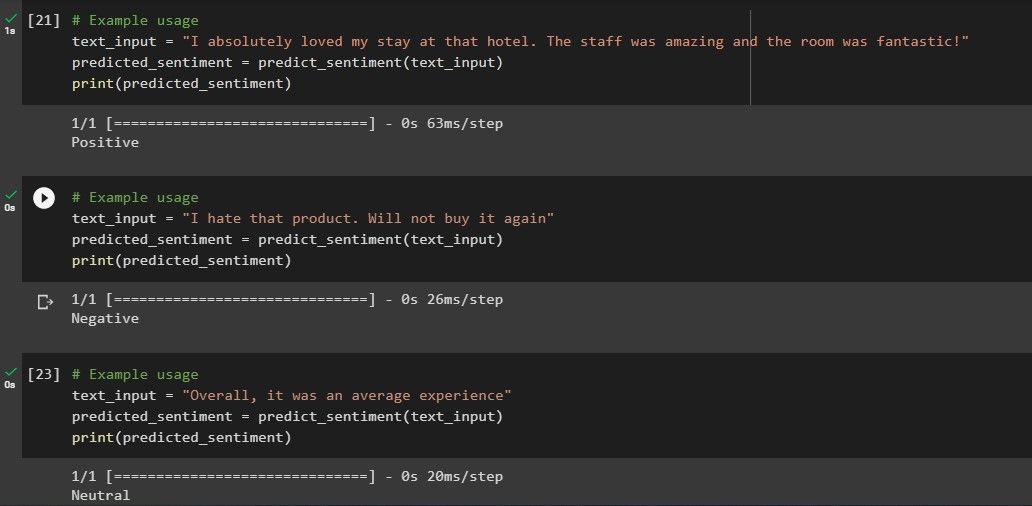
این مدل قادر است احساسات هر سه بررسی را به درستی طبقه بندی کند.
پیش بینی احساسات با استفاده از مدل های از پیش آموزش دیده
گاهی اوقات در یادگیری ماشینی، ممکن است با چالش پیدا کردن مجموعه داده مناسب مواجه شوید. همچنین ممکن است منابع لازم برای ایجاد مجموعه داده خود را نداشته باشید. اینجاست که مدل های از پیش آموزش دیده وارد می شوند. شما باید بدانید که چگونه از API آنها استفاده کنید و آنها را به عهده بقیه بگذارید.