
با مقدار کمی کد و چند کتابخانه مفید، می توانید این ابزار قدرتمند تجزیه و تحلیل اسناد را بسازید.
استخراج بینش از اسناد و داده ها در تصمیم گیری آگاهانه بسیار مهم است. با این حال، نگرانی های مربوط به حریم خصوصی هنگام برخورد با اطلاعات حساس ایجاد می شود. LangChain، در ترکیب با OpenAI API، به شما امکان می دهد اسناد محلی خود را بدون نیاز به آپلود آنلاین آنها تجزیه و تحلیل کنید.
آنها با نگهداشتن دادههای شما به صورت محلی، استفاده از تعبیهها و بردارسازی برای تجزیه و تحلیل، و اجرای فرآیندها در محیط شما به این امر دست مییابند. OpenAI از داده های ارسال شده توسط مشتریان از طریق API برای آموزش مدل های خود یا بهبود خدمات خود استفاده نمی کند.
تنظیم محیط
یک محیط مجازی پایتون جدید ایجاد کنید. این اطمینان حاصل می کند که هیچ تضاد نسخه کتابخانه وجود ندارد. سپس دستور ترمینال زیر را برای نصب کتابخانه های مورد نیاز اجرا کنید.
pip install langchain openai tiktoken faiss-cpu pypdf
در اینجا خلاصه ای از نحوه استفاده از هر کتابخانه آورده شده است:
- LangChain: شما از آن برای ایجاد و مدیریت زنجیره های زبانی برای پردازش و تجزیه و تحلیل متن استفاده خواهید کرد. ماژول هایی برای بارگذاری اسناد، تقسیم متن، جاسازی ها و ذخیره سازی برداری ارائه می دهد.
- OpenAI: شما از آن برای اجرای پرس و جوها و به دست آوردن نتایج از یک مدل زبان استفاده خواهید کرد.
- tiktoken: از آن برای شمارش تعداد نشانهها (واحدهای متن) در یک متن استفاده میکنید. این برای پیگیری تعداد توکن ها هنگام تعامل با OpenAI API است که بر اساس تعداد توکن هایی که استفاده می کنید شارژ می شود.
- FAISS: از آن برای ایجاد و مدیریت یک فروشگاه برداری استفاده خواهید کرد که امکان بازیابی سریع بردارهای مشابه را بر اساس جاسازی آنها فراهم می کند.
- PyPDF: این کتابخانه متن را از PDF استخراج می کند. این به بارگیری فایل های PDF و استخراج متن آنها برای پردازش بیشتر کمک می کند.
پس از نصب تمام کتابخانه ها، محیط شما اکنون آماده است.
دریافت کلید OpenAI API
وقتی به OpenAI API درخواست می کنید، باید یک کلید API را به عنوان بخشی از درخواست اضافه کنید. این کلید به ارائهدهنده API اجازه میدهد تأیید کند که درخواستها از یک منبع قانونی میآیند و شما مجوزهای لازم برای دسترسی به ویژگیهای آن را دارید.
برای دریافت کلید OpenAI API، به پلتفرم OpenAI بروید.
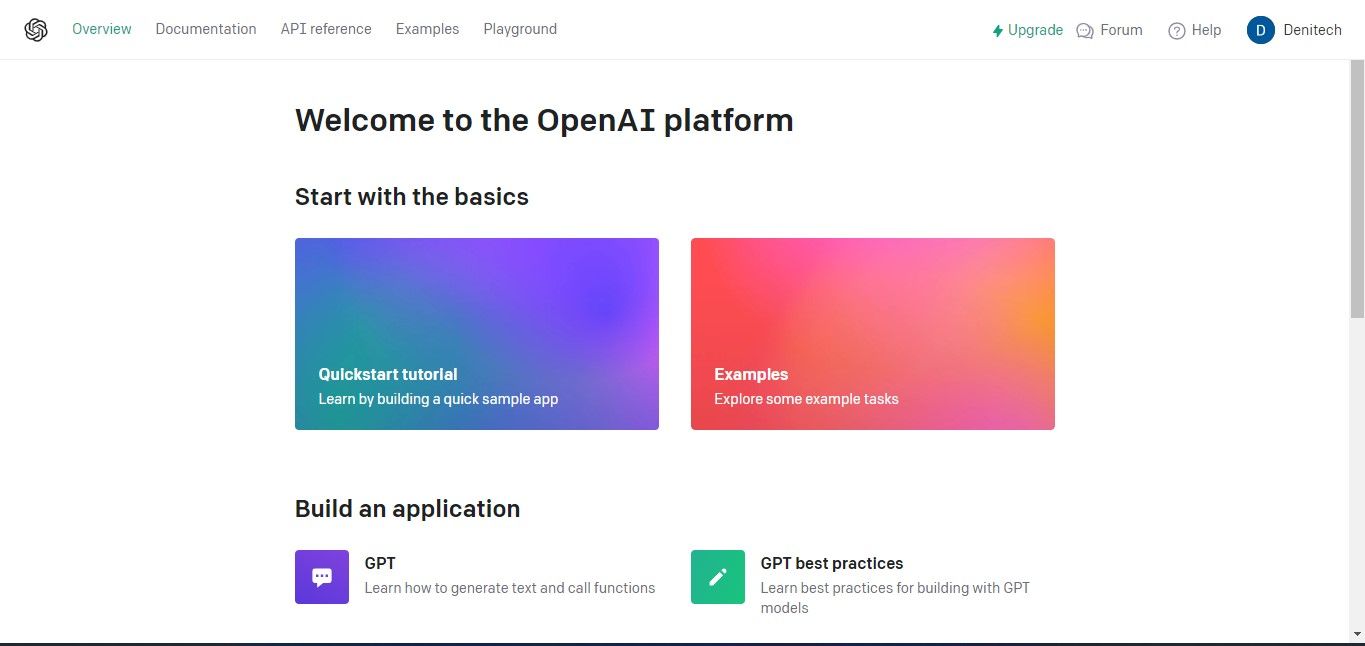
سپس، در زیر نمایه حساب خود در بالا سمت راست، روی View keys API کلیک کنید. صفحه کلیدهای API ظاهر می شود.
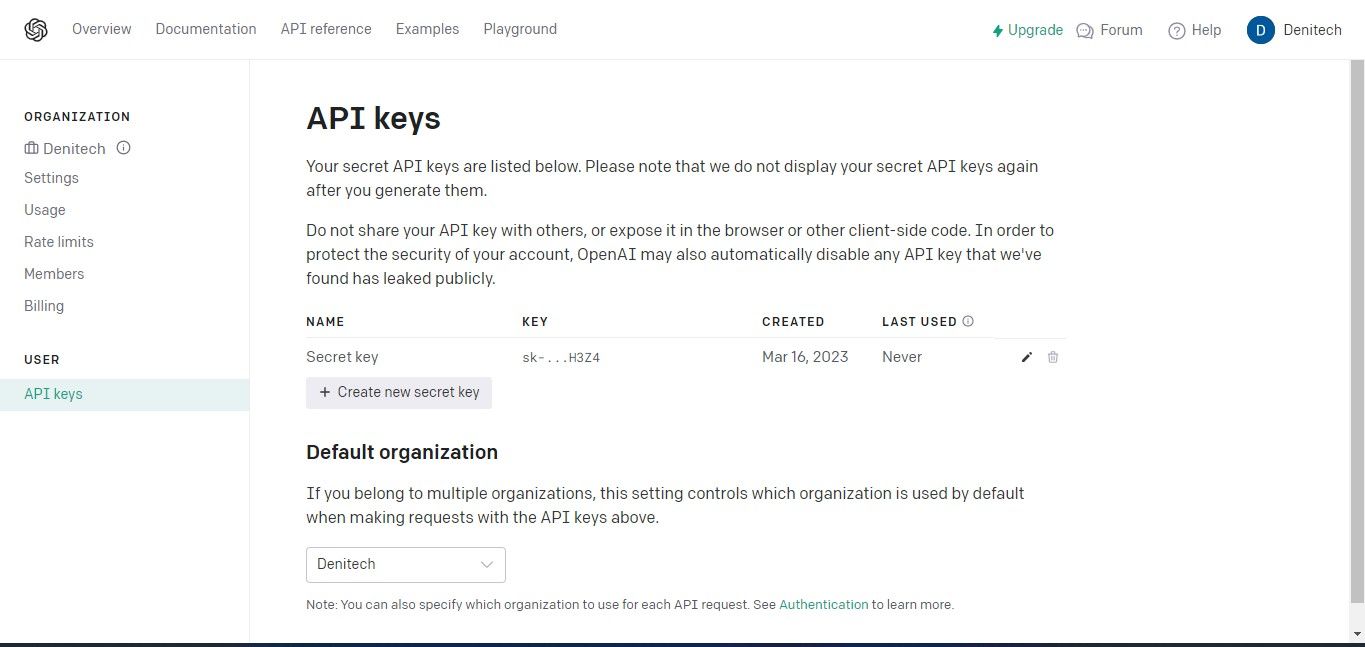
بر روی دکمه Create new secret key کلیک کنید. کلید خود را نام ببرید و روی Create new secret key کلیک کنید. OpenAI کلید API شما را تولید می کند که باید آن را کپی کرده و در جایی امن نگهداری کنید. به دلایل امنیتی، نمیتوانید دوباره آن را از طریق حساب OpenAI خود مشاهده کنید. اگر این کلید مخفی را گم کردید، باید یک کلید جدید ایجاد کنید.
کد منبع کامل در یک مخزن GitHub موجود است.
واردات کتابخانه های مورد نیاز
برای اینکه بتوانید از کتابخانه های نصب شده در محیط مجازی خود استفاده کنید، باید آنها را وارد کنید.
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
توجه داشته باشید که کتابخانههای وابستگی را از LangChain وارد میکنید. این به شما امکان می دهد از ویژگی های خاص چارچوب LangChain استفاده کنید.
بارگیری سند برای تجزیه و تحلیل
با ایجاد متغیری که کلید API شما را نگه می دارد شروع کنید. از این متغیر بعداً در کد برای احراز هویت استفاده خواهید کرد.
# Hardcoded API key
openai_api_key = "Your API key"
اگر میخواهید کد خود را با اشخاص ثالث به اشتراک بگذارید، توصیه نمیشود کلید API خود را کدگذاری سخت کنید. برای کد تولیدی که قصد توزیع آن را دارید، به جای آن از یک متغیر محیطی استفاده کنید.
بعد، یک تابع ایجاد کنید که یک سند را بارگیری کند. تابع باید یک PDF یا یک فایل متنی بارگیری کند. اگر سند هیچکدام از این دو نباشد، تابع باید یک ValueError ایجاد کند.
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")
پس از بارگذاری اسناد، یک CharacterTextSplitter ایجاد کنید. این تقسیم کننده اسناد بارگذاری شده را بر اساس کاراکترها به قطعات کوچکتر تقسیم می کند.
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)
تقسیم سند تضمین میکند که تکهها اندازه قابل مدیریتی دارند و همچنان با زمینههای همپوشانی مرتبط هستند. این برای کارهایی مانند تجزیه و تحلیل متن و بازیابی اطلاعات مفید است.
استعلام سند
شما به راهی برای پرس و جو در مورد سند آپلود شده نیاز دارید تا از آن بینش دریافت کنید. برای انجام این کار، تابعی ایجاد کنید که یک رشته کوئری و یک بازیابی را به عنوان ورودی می گیرد. سپس یک نمونه RetrievalQA با استفاده از retriever و یک نمونه از مدل زبان OpenAI ایجاد می کند.
def query_pdf(query, retriever):
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),
chain_type="stuff", retriever=retriever)
result = qa.run(query)
print(result)
این تابع از نمونه QA ایجاد شده برای اجرای پرس و جو و چاپ نتیجه استفاده می کند.
ایجاد تابع اصلی
تابع اصلی جریان کلی برنامه را کنترل خواهد کرد. ورودی کاربر را برای نام فایل سند می گیرد و آن سند را بارگیری می کند. سپس یک نمونه OpenAIEmbeddings برای embedding ها ایجاد کنید و یک فروشگاه برداری بر اساس اسناد و جاسازی های بارگذاری شده بسازید. این فروشگاه برداری را در یک فایل محلی ذخیره کنید.
در مرحله بعد، ذخیره وکتور ماندگار را از فایل محلی بارگیری کنید. سپس حلقه ای را وارد کنید که کاربر بتواند پرس و جوها را وارد کند. تابع اصلی این پرسوجوها را به همراه retriever ذخیرهسازی بردار پایدار به تابع query_pdf ارسال میکند. حلقه تا زمانی که کاربر وارد “خروج” شود ادامه خواهد داشت.
def main():
filename = input("Enter the name of the document (.pdf or .txt):\n")
docs = load_document(filename)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index_constitution")
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
query = input("Type in your query (type 'exit' to quit):\n")
while query != "exit":
query_pdf(query, persisted_vectorstore.as_retriever())
query = input("Type in your query (type 'exit' to quit):\n")
تعبیهها روابط معنایی بین کلمات را نشان میدهند. وکتورها فرمی هستند که در آن می توانید تکه هایی از متن را نشان دهید.
این کد با استفاده از جاسازی های ایجاد شده توسط OpenAIEmbeddings، داده های متنی موجود در سند را به بردار تبدیل می کند. سپس این بردارها را با استفاده از FAISS برای بازیابی و مقایسه موثر بردارهای مشابه نمایه می کند. این چیزی است که امکان تجزیه و تحلیل سند بارگذاری شده را فراهم می کند.
در نهایت، از ساختار __name__ == “__main__” برای فراخوانی تابع main استفاده کنید، اگر کاربر برنامه را به صورت مستقل اجرا کند:
if __name__ == "__main__":
main()
این برنامه یک برنامه خط فرمان است. به عنوان یک افزونه، می توانید از Streamlit برای افزودن یک رابط وب به برنامه استفاده کنید.
انجام تجزیه و تحلیل اسناد
برای انجام تجزیه و تحلیل اسناد، سندی را که می خواهید آنالیز کنید در همان پوشه پروژه خود ذخیره کنید، سپس برنامه را اجرا کنید. نام سندی را که میخواهید تجزیه و تحلیل کنید را میپرسد. نام کامل آن را وارد کنید، سپس پرس و جوهایی را برای تجزیه و تحلیل برنامه وارد کنید.
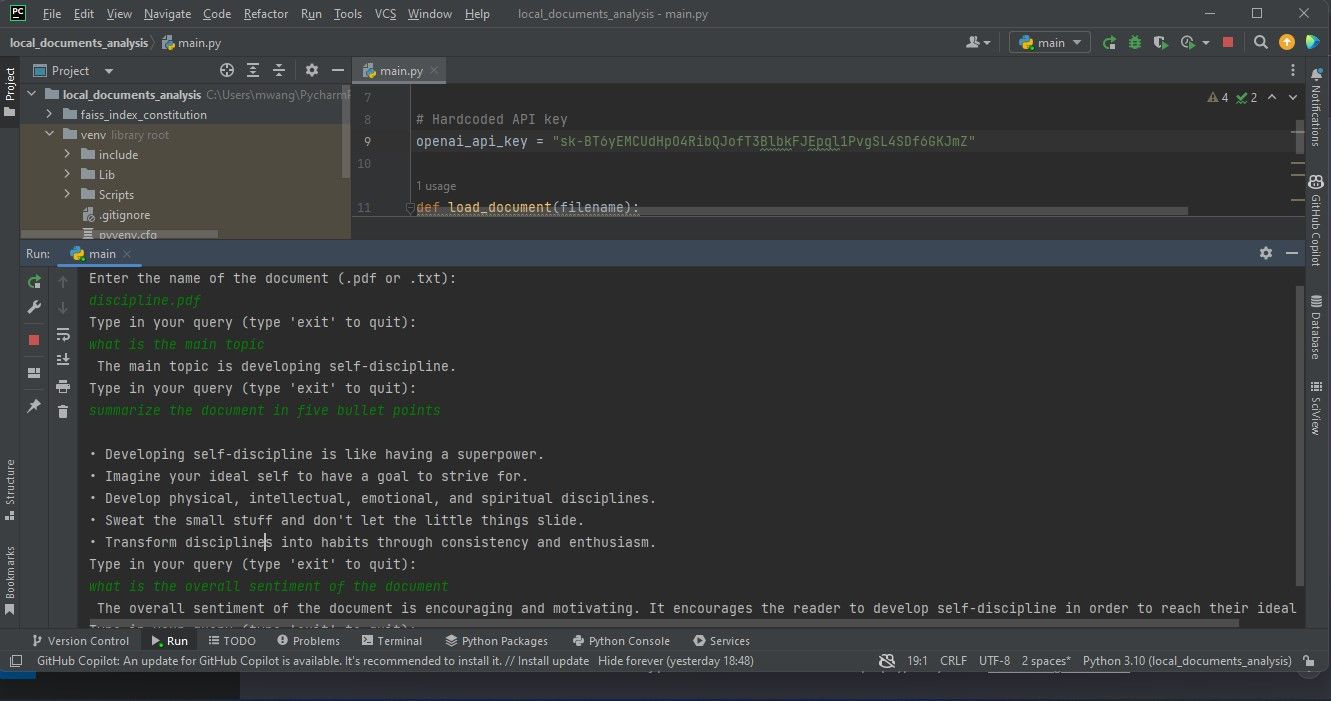
اسکرین شات زیر نتایج تجزیه و تحلیل یک PDF را نشان می دهد.
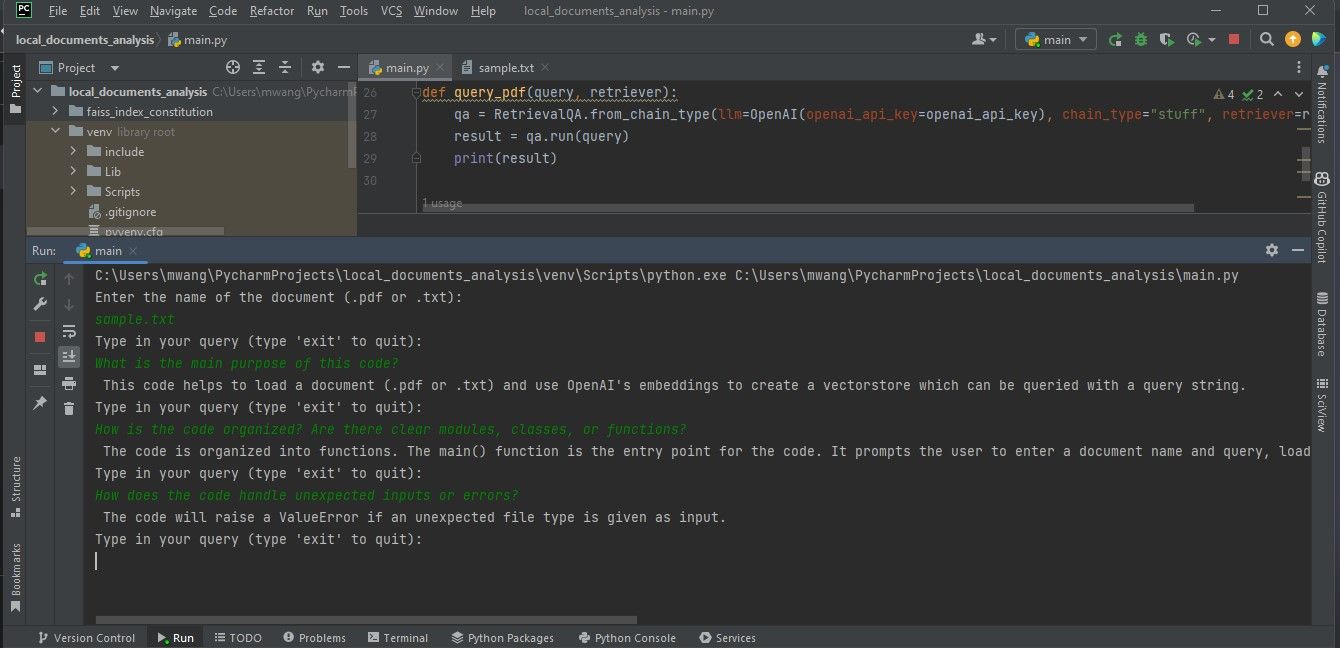
خروجی زیر نتایج تجزیه و تحلیل یک فایل متنی حاوی کد منبع را نشان می دهد.
اطمینان حاصل کنید که فایل هایی که می خواهید تجزیه و تحلیل کنید در قالب PDF یا متن هستند. اگر اسناد شما در قالب های دیگری هستند، می توانید با استفاده از ابزارهای آنلاین آنها را به فرمت PDF تبدیل کنید.
درک فناوری پشت مدل های زبان بزرگ
LangChain ایجاد برنامه های کاربردی را با استفاده از مدل های زبان بزرگ ساده می کند. این همچنین به این معنی است که آنچه در پشت صحنه می گذرد را انتزاعی می کند. برای درک دقیق نحوه عملکرد برنامه ای که ایجاد می کنید، باید خود را با فناوری پشت مدل های زبان بزرگ آشنا کنید.