Excel با توابع فراوان پر شده است، اما اگر هنوز به VLOOKUP، عبارات IF تو در تو یا CONCATENATE وابسته باشید، برگههایتان را سختتر از لازم مدیریت میکنید. مایکروسافت توابع جدیدتر و قدرتمندتری در اکسل دارد که حس جادوگری در کاربرگ به شما میدهد و فرمولهایتان را خواناتر میکند.
Excel پر از توابع است، اما اگر هنوز به VLOOKUP، عبارات IF تو در تو یا CONCATENATE وابسته باشید، باعث میشوید که برگههای کاریتان سختتر از حد لازم مدیریت شوند. مایکروسافت توابع جدیدتر و قدرتمندتری دارد که حس یک جادوگر برگهکاری به شما میدهند و فرمولهای شما را خواناتر میکند.
خبر خوب این است که نیازی به متخصص بودن در Excel ندارید—آنها طوری طراحی شدهاند که جایگزین توابع کند و قدیمی شوند که احتمالاً با آنها آشنایی دارید. چه دادهای را جستجو میکنید، فهرستهای پویا میسازید یا با متن کار میکنید، ابزارهای بهتری درون Excel وجود دارند که میتوانند در زمان شما صرفهجویی کنند.
5 جایگزینی VLOOKUP محدود کننده
XLOOKUP بسیار انعطافپذیرتر است
VLOOKUP سالها تابع اصلی برای جستجوی دادهها در Excel بوده است، اما محدودیتهایی دارد. میتوانید فقط در ستون palingچپ جستجو کنید و مقادیر را به سمت راست برگردانید. اگر ستون جستجوی شما در سمت چپ نباشد، مجبور شوید کل جدول را دوبارهچین کنید یا ستونهای کمکی اضافه کنید.
XLOOKUP همه این مشکلات را حل میکند. میتواند در هر جایی از جدول شما جستجو کند و مقادیر را از هر ستونی برگرداند—چه به سمت چپ، راست یا هر جهت دیگر. بهعلاوه، نگارش آن سادهتر و به خاطر سپردن راحتتر است.
اینجا مقایسهٔ نگارشها آورده شده است:
VLOOKUP:
=VLOOKUP(lookup_value, table_array, col_index_num, [range_lookup])
- lookup_value: مقداری که جستجو میکنید.
- table_array: بازهای که دادههای شما در آن قرار دارد.
- col_index_num: شماره ستونی که میخواهید مقدار را از آن برگردانید (از سمت چپ شمارش میشود).
- range_lookup: TRUE برای مطابقت تقریبی، FALSE برای مطابقت دقیق.
XLOOKUP:
=XLOOKUP(lookup_value, lookup_array, return_array, [if_not_found], [match_mode], [search_mode])
- lookup_value: مقداری که جستجو میکنید.
- lookup_array: ستونی که میخواهید در آن جستجو کنید.
- return_array: ستونی که میخواهید نتیجه از آن برگردانده شود.
شما همچنین میتوانید پارامترهای اختیاری زیر را استفاده کنید:
- if_not_found: پیام سفارشی اگر مطابقتی یافت نشد.
- match_mode: مطابقت دقیق (0) یا انواع دیگر مطابقت.
- search_mode: جستجو از ابتدا به انتها یا بالعکس.
فرض کنید جدول فروش با شناسههای محصول در ستون A، نام محصول در ستون B و قیمتها در ستون C دارید. اگر بخواهید قیمت شناسه محصول «PR-12-Y» را پیدا کنید، VLOOKUP نیاز دارد تا شماره ستون را بدانید که قیمت در ستون سوم قرار دارد:
=VLOOKUP("PR-12-Y", A2:C100, 3, FALSE)
با XLOOKUP تنها کافیست ستونهای مورد جستجو و بازگشت را مشخص کنید:
=XLOOKUP("PR-12-Y", A2:A100, C2:C100)
اگر بعداً ستونی جدید بین نام محصول و قیمت اضافه کنید، فرمول VLOOKUP خراب میشود چون شماره ستون دیگر صحیح نیست. XLOOKUP همچنان کار میکند چون به بازههای واقعی ستونها ارجاع میدهد، نه یک عدد. شما همچنین میتوانید از XLOOKUP برای جستجو در ستون C و بازگرداندن مقادیر از ستون A استفاده کنید—چیزی که VLOOKUP نمیتواند انجام دهد.
XLOOKUP تنها در Microsoft 365 و Excel 2021 یا نسخههای بعدی موجود است. اگر از نسخهٔ قدیمیتر استفاده میکنید، باید به VLOOKUP بچسبید یا اشتراک Excel خود را ارتقا دهید.
4 دور کردن عبارات IF تو در تو نامنظم
تابع IFS بسیار تمیزتر است
عبارات IF تو در تو بهسرعت دستپاچه میشوند. وقتی چندین شرط را تست میکنید، فرمول پر از پرانتز میشود و تقریباً خواندن یا عیبیابی آن غیرممکن است. یک پرانتز بستهٔ گمشده، کل چیز را خراب میکند.
تابع IFS این مشکل را حل میکند؛ به شما اجازه میدهد چندین شرط را در یک فرمول ساده تست کنید. بنابراین دیگر نیازی به تو در تو بودن نیست؛ فقط شرطها و نتایج مربوطه را بهترتیب بنویسید.
اینجا مقایسهٔ نگارشها آورده شده است:
IF تو در تو:
=IF(condition1, value1, IF(condition2, value2, IF(condition3, value3, value4)))
IFS:
=IFS(condition1, value1, condition2, value2, condition3, value3, TRUE, default_value)
- condition1, condition2, condition3: آزمایشهای منطقی برای ارزیابی.
- value1, value2, value3: نتایجی که اگر هر شرط TRUE باشد برگردانده میشوند.
- TRUE, default_value: گزینهٔ پیشفرض برای زمانی که هیچ شرطی برقرار نشود.
فرض کنید با دادههای فروش کار میکنید و میخواهید بر اساس مجموع فروش رتبه عملکرد اختصاص دهید. با عبارات IF تو در تو، فرمول به این شکل خواهد بود:
=IF(G2>=5000, "Excellent", IF(G2>=4000, "Good", IF(G2>=3000, "Average", "Below Average")))
این خواندن دشوار است و اگر بخواهید شرط دیگری اضافه کنید یا آستانهای را تغییر دهید، باید بین پرانتزها جستجو کنید. با IFS، همان منطق بسیار تمیزتر است:
=IFS(G2>=5000, "Excellent", G2>=4000, "Good", G2>=3000, "Average", TRUE, "Below Average")
هر شرط واضح است و میتوانید به راحتی آستانهها و رتبهها را مشاهده کنید. اگر بخواهید «Good» را از ۴٬۵۰۰ بهجای ۴٬۰۰۰ آغاز کنید، فقط کافیست همان خط را ویرایش کنید. TRUE در انتها بهعنوان یک پیشفرض برای همهٔ مواردی که شرط قبلی را برآورده نمیکنند عمل میکند—اساساً جایگزین «else» در IF تو در تو است.
3 دست کشیدن از CONCATENATE خستهکننده
به تابع قدرتمند TEXTJOIN سوئیچ کنید
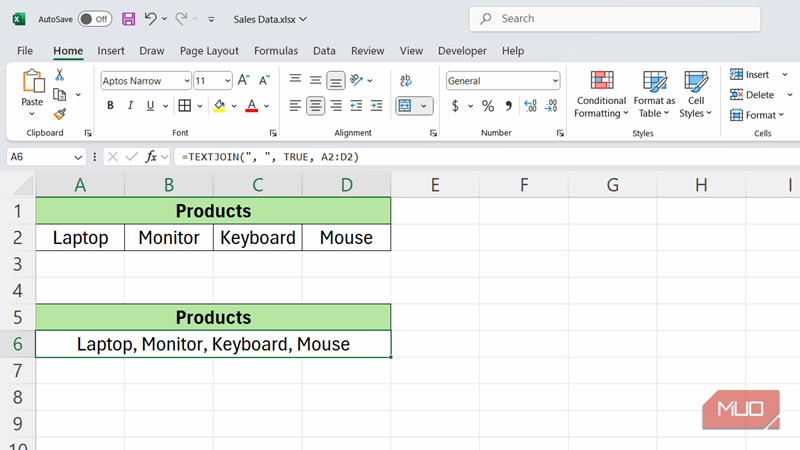
CONCATENATE مجبور میکند که هر سلول را بهصورت جداگانه ارجاع دهید و جداکنندهها (مانند کاما یا فاصله) را بهدستانداخته بنویسید. اگر پنج سلول را ترکیب کنید، پنج ارجاع سلولی بهعلاوهٔ چهار جداکننده مینویسید.
TEXTJOIN این کار را یک بار انجام میدهد. یکبار جداکننده را تعریف میکنید، میگویید آیا سلولهای خالی را نادیده بگیرید یا نه، سپس کل محدوده را انتخاب میکنید. نوشتن سریعتر و ویرایش بعدی بسیار آسانتر است.
در اینجا مقایسهٔ نگارشها آمده است:
CONCATENATE:
=CONCATENATE(text1, " ", text2, " ", text3)
TEXTJOIN:
=TEXTJOIN(delimiter, ignore_empty, text1, [text2], ...)
- delimiter: کاراکتر یا متنی که بین هر مقدار قرار میگیرد (کاما، فاصله، خط تیره و غیره).
- ignore_empty: TRUE برای نادیده گرفتن سلولهای خالی، FALSE برای شامل کردنشان.
- text1, [text2], …: سلولها یا محدودههایی که میخواهید ترکیب کنید.
فرض کنید لیستی از محصولات در ستونهای A تا D دارید و میخواهید یک رشتهٔ تکخطی بسازید که تمام چهار مورد را با کاما جدا کند. با CONCATENATE مینویسید:
=CONCATENATE(A2, ", ", B2, ", ", C2, ", ", D2)
این کار میکند، اما اگر یک سلول خالی باشد، همچنان کاما و فاصله میمانند. با TEXTJOIN میتوانید این کار را اینگونه انجام دهید:
=TEXTJOIN(", ", TRUE, A2:D2)
آرگومان TRUE به Excel میگوید که سلولهای خالی را نادیده بگیرد تا در خروجی کاما یا فاصلهٔ اضافی نداشته باشید. اگر نام محصولات، مناطق فروش یا هر دادهای که ممکن است برخی سلولها خالی باشند ترکیب کنید، این روش خروجی تمیزتری میدهد.
TEXTJOIN همچنین میتواند بر روی محدودههای بزرگتر کار کند. اگر میخواهید ۲۰ سلول را ترکیب کنید، نیازی به نوشتن ۲۰ ارجاع نیست—فقط یکبار محدوده را مشخص میکنید.
2 فراموش کردن ساختن فهرست دستی
از آرایههای دینامیک مثل FILTER و UNIQUE استفاده کنید
ساختن فهرستهای فیلتر شده بهصورت دستی یعنی ردیفها را یکییکی کپی کنید یا از AutoFilter استفاده کنید، سپس نتایج را به مکان دیگری بچسبانید. اگر دادهٔ منبع تغییر کند، باید تمام فرآیند را از سر بگیرید. این کار زمانبر است و مستعد خطا میشود.
توابع آرایهای دینامیک مثل FILTER و UNIQUE فهرستها را بهصورت خودکار تولید میکنند و در زمان واقعی بهروزرسانی میشوند هرگاه دادهٔ منبع تغییر کند. فقط یکبار فرمول را مینویسید و Excel بقیه را مدیریت میکند. من از تابع FILTER اکسل برای همهٔ کارها استفاده میکنم، چون نیازی به تازهسازی یا کپی‑پیست دستی ندارم.
نگارش هر دو تابع به این شکل است:
FILTER:
=FILTER(array, include, [if_empty])
- array: بازهٔ دادهای که میخواهید فیلتر کنید.
- include: شرطی که تعیین میکند کدام ردیفها گنجانده شوند.
- if_empty: پیام اختیاری برای نمایش اگر هیچ نتیجهای با شرط مطابقت نداشته باشد.
UNIQUE:
=UNIQUE(array, [by_col], [exactly_once])
- array: بازهای که میخواهید مقادیر یکتای آن را استخراج کنید.
- by_col: FALSE برای مقایسهٔ ردیفها (پیشفرض)، TRUE برای مقایسهٔ ستونها.
- exactly_once: FALSE همهٔ مقادیر یکتا را برمیگرداند، TRUE فقط مقادیری که دقیقاً یک بار ظاهر میشوند.
فرض کنید جدول فروش با شناسهٔ محصول، نام محصول، نواحی و اعداد فروش دارید. اگر فقط فروشهای ناحیهٔ «East» را میخواهید، میتوانید از FILTER استفاده کنید:
=FILTER(B2:H33, B2:B33="East", "No results found")
این تمام ردیفهایی که ناحیه در ستون B برابر «East» باشد برمیگرداند. اگر شخصی فروش جدیدی در ناحیهٔ «East» اضافه کند، بهصورت خودکار در فهرست فیلتر شده ظاهر میشود. پیام «No results found» در صورتی که هیچ ردیفی مطابقت نداشته باشد نمایش داده میشود.
برای UNIQUE، اگر میخواهید فهرست تمیزی از تمام دستهبندیهای محصول بدون تکرار داشته باشید، مینویسید:
=UNIQUE(C2:C33)
این ستون C را اسکن میکند و هر دستهٔ محصول یکتا را یکبار برمیگرداند. اگر همان محصول ۲۰ بار در دادهٔ منبع ظاهر شود، فقط یکبار در نتایج نشان داده میشود. میتوانید هر دو تابع را ترکیب کنید—ابتدا دادهها را فیلتر کنید، سپس مقادیر یکتا را از نتایج فیلتر شده استخراج کنید.
توابع آرایهای دینامیک به Microsoft 365 یا Excel 2021 نیاز دارند. اگر نسخهٔ شما از اینها پشتیبانی نمیکند، فرمولها #NAME? برمیگردانند، یکی از خطاهای رایج اکسل.
1 جایگزینی LEFT, RIGHT و MID
چون TEXTSPLIT، TEXTBEFORE و TEXTAFTER شهودیتر هستند
LEFT، RIGHT و MID نیاز به شمارش دقیق تعداد کاراکترها برای استخراج دارند. اگر قالب متن تغییر کند یا طول آن متفاوت باشد، دائماً باید شمارشها را تنظیم کنید و یک محاسبهٔ نادرست تمام فرمول را خراب میکند.
توابع متن جدید—TEXTSPLIT، TEXTBEFORE و TEXTAFTER—به شما اجازه میدهند متن را بر پایهٔ جداکنندهها یا علامتهای خاص استخراج کنید نه بر پایهٔ موقعیت کاراکترها. آنها از جمله توابعی هستند که من بیشتر استفاده میکنم، بهدلیل انعطافپذیری و درک سریعشان.
در اینجا نگارش هر یک آورده شده است:
TEXTSPLIT:
=TEXTSPLIT(text, col_delimiter, [row_delimiter], [ignore_empty], [match_mode], [pad_with])
- text: رشتهٔ متنی که میخواهید تقسیم کنید.
- col_delimiter: کاراکتری که ستونها را جدا میکند (کاما، فاصله، خط تیره و غیره).
- row_delimiter: کاراکتر اختیاری که ردیفها را جدا میکند.
- ignore_empty: TRUE برای نادیده گرفتن مقادیر خالی، FALSE برای شامل کردنشان.
- match_mode: 0 برای حساس به حروف، 1 برای غیر حساس.
- pad_with: مقداری که برای سلولهای خالی در نتیجه استفاده میشود.
TEXTBEFORE:
=TEXTBEFORE(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])
- text: رشتهٔ متنی که میخواهید جستجو کنید.
- delimiter: کاراکتر یا متنی که نشان میدهد تا چه جایی استخراج شود.
- instance_num: کدام رخداد جداکننده را استفاده میکنید (۱ برای اولین، ۲ برای دومین و غیره).
- match_mode: 0 برای حساس به حروف، 1 برای غیر حساس.
- match_end: 0 برای جستجو از ابتدا، 1 برای جستجو از انتها.
- if_not_found: مقداری که اگر جداکننده یافت نشد برگردانده میشود.
TEXTAFTER:
=TEXTAFTER(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])
پارامترها مشابه TEXTBEFORE هستند، اما متن پس از جداکننده استخراج میشود.
فرض کنید کدهای محصول به شکل «PRD-12345-X» هستند و میخواهید فقط قسمت میانی را استخراج کنید. با MID باید تعداد کاراکترها را بشمارید:
=MID(A2, 5, 5)
این فقط وقتی کار میکند که «12345» همواره پنج کاراکتر باشد. با TEXTBEFORE و TEXTAFTER میتوانید بر پایهٔ خط تیره استخراج کنید:
=TEXTAFTER(TEXTBEFORE(A2, "-", 2), "-")
این ابتدا همه چیز را پیش از خط تیرهٔ دوم میگیرد، سپس پس از خط تیرهٔ اول در آن نتیجه را استخراج میکند. اگر کد محصول به «PRD-12345-X» تغییر کند، همچنان بدون نیاز به تنظیم شمارش کاراکترها کار میکند.
برای TEXTSPLIT، اگر نامهای کامل را به شکل «First Last» داشته باشید و بخواهید به دو ستون جدا کنید، مینویسید:
=TEXTSPLIT(E2, " ")
Excel بهصورت خودکار نام را در نقطهٔ فاصله تقسیم میکند و نام و نام خانوادگی را در ستونهای جداگانه میگذارد. با LEFT و RIGHT نیاز به فرمولهای جداگانه و استفاده از FIND برای یافتن فاصله دارید که خیلی پیچیدهتر است.
با جایگزینی یک تابع شروع کنید و از آن ساخته شوید
توابع قدیمی هنوز کار میکنند، بنابراین Excel شما را مجبور به تعویض نمیکند. اما اگر زمان بیشتری را صرف رفع خطاهای فرمول یا شمارش دستی کاراکترها میکنید، گزینههای جدید ارزش امتحان دارند.
یک تابع از این فهرست را که بهطور مرتب استفاده میکنید (مثلاً VLOOKUP یا عبارات IF تو در تو) انتخاب کنید. آن را در یک برگهٔ کاری جایگزین کنید و ببینید چگونه کار میکند. وقتی با نگارش راحت شوید، صرفهجوییهای زمانی بهسرعت انباشته میشود.