جداول محوری مدتهاست که ابزاری استاندارد برای جمع بندی و تجزیه و تحلیل داده ها در اکسل بوده است و آنها برای بسیاری از کارها به خوبی کار می کنند. اما اگر تا به حال خود را پیدا کرده اید که فقط برای تنظیم گروه بندی یا تازه کردن داده های خود از طریق منوهای مختلف کلیک می کنید ، ممکن است از یک رویکرد آسان تر قدردانی کنید. توابع Groupby و Pivotby Excel روش متفاوتی برای جمع آوری و سازماندهی داده ها ارائه می دهند – این انعطاف پذیر و شفاف تر از رابط جدول محوری است.
جداول محوری مدتهاست که ابزاری استاندارد برای جمع بندی و تجزیه و تحلیل داده ها در اکسل بوده است و آنها برای بسیاری از کارها به خوبی کار می کنند. اما اگر تا به حال خود را پیدا کرده اید که فقط برای تنظیم گروه بندی یا تازه کردن داده های خود از طریق منوهای مختلف کلیک می کنید ، ممکن است از یک رویکرد آسان تر قدردانی کنید. توابع Groupby و Pivotby Excel روش متفاوتی برای جمع آوری و سازماندهی داده ها ارائه می دهند – این انعطاف پذیر و شفاف تر از رابط جدول محوری است.
من از این توابع برای خلاصه کردن داده ها با فرمول ها به جای کادرهای گفتگو استفاده می کنم. این امر می تواند دقیقاً آنچه را که اتفاق می افتد و تجزیه و تحلیل تنظیم در پرواز را آسان تر می کند. اگر با فرمول های اکسل نیز راحت هستید ، Groupby و Pivotby می توانند گردش کار شما را سهولت داده و کنترل بیشتری در مورد نحوه ساخت داده های شما داشته باشند.
Groupby عملکردی برای جمع آوری داده های ساده است
ایجاد گزارش های خلاصه را ساده می کند
عملکرد Groupby دقیقاً همان چیزی را که نام آن نشان می دهد انجام می دهد. IT ردیف داده ها را بر اساس یک یا چند ستون گروه بندی می کند و مقادیر خلاصه را برای هر گروه محاسبه می کند. من از آن برای نمایش کل فروش بر اساس منطقه یا متوسط درآمد بر اساس محصول بدون تنظیم جدول محوری استفاده می کنم.
بیایید بگوییم که شما در مناطق و محصولات مختلف یک معاملات ردیابی مجموعه داده های فروش دارید. با استفاده از GroupBy ، می توانید از جداول محوری تغییر دهید و به تجزیه و تحلیل خود اجازه می دهید خود را به روز کند و کلیت های خود را در یک فرمول واحد بدست آورد.
از نحو زیر استفاده می کند:
= Groupby (row_fields ، مقادیر ، عملکرد ، [field_headers] ، [total_depth] ، [sort_order] ، [filter_array] ، [field_relationship])
پارامترها مانند این تجزیه می شوند:
- row_fields: ستون یا ستون هایی که می خواهید توسط آنها گروه بندی کنید. در صورت نیاز به گروه بندی تو در تو ، این می تواند یک ستون واحد مانند منطقه یا ستون های مختلف باشد – برای مثال ، منطقه و محصول با هم.
- مقادیر: داده هایی که می خواهید جمع کنید. این به طور معمول ستونی از اعدادی است که می خواهید خلاصه کنید ، به طور متوسط یا شمارش کنید.
- عملکرد: محاسبه برای انجام در هر گروه. گزینه های متداول شامل جمع ، میانگین ، تعداد ، حداکثر و حداقل است. می توانید از هر عملکردی که با آرایه کار می کند استفاده کنید.
موارد زیر پارامترهای اختیاری است:
- field_headers: این را روی 1 تنظیم کنید تا هدرهای ستون را در خروجی قرار دهید ، یا 0 را برای حذف آنها قرار دهید. اگر این موضوع را از بین ببرید ، اکسل به طور پیش فرض عنوان را شامل می شود.
- total_depth: این باعث می شود ردیف های بزرگ به نتایج شما اضافه شود. آن را برای یک کل بزرگ ، 2 برای Subtotals و جمع های بزرگ و غیره روی 1 تنظیم کنید.
- SORT_ORDER: نحوه طبقه بندی گروه ها را کنترل می کند. از 1 برای صعود ، -1 برای نزولی استفاده کنید ، یا آن را حذف کنید تا سفارش اصلی از داده های خود نگه دارید.
- Filter_Array: یک آرایه واقعی/نادرست که فیلترهایی که قبل از گروه بندی ردیف می کنند. این امر هنگامی مفید است که فقط می خواهید زیر مجموعه ای از داده های خود را جمع کنید.
- FIELD_RELATIONSHIP: کنترل می کند که چگونه اکسل رابطه بین چند ردیف را هنگام گروه بندی تفسیر می کند. برای درمان هر ترکیبی از مقادیر به عنوان یک گروه منحصر به فرد ، روی 0 (یا حذف) تنظیم کنید. برای ایجاد یک رابطه سلسله مراتبی که در آن زمینه دوم تحت عنوان اول قرار دارد ، روی 1 تنظیم کنید.
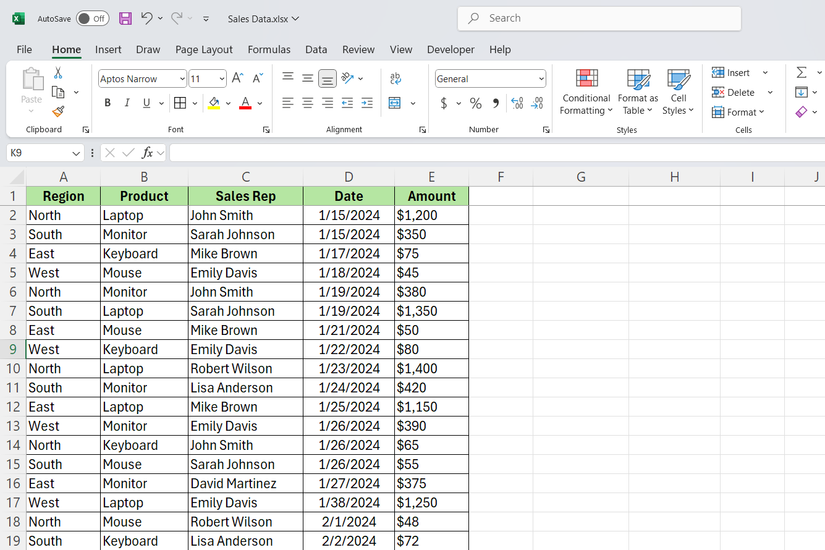
در صفحه گسترده فروش ، سوابق معامله را با ستون های منطقه ، محصول ، فروش ، تاریخ و ستون های مبلغ پیدا خواهید کرد. برای محاسبه کل فروش بر اساس منطقه ، شما استفاده می کنید:
= Groupby (A2: A50 ، E2: E50 ، جمع)
این همه ردیف های منطقه (ستون A) را گروه بندی می کند و مقادیر مقدار مربوطه (ستون E) را خلاصه می کند. نتیجه یک جدول دو ستونی است که هر منطقه و کل فروش آن را نشان می دهد-جدول محوری لازم نیست.
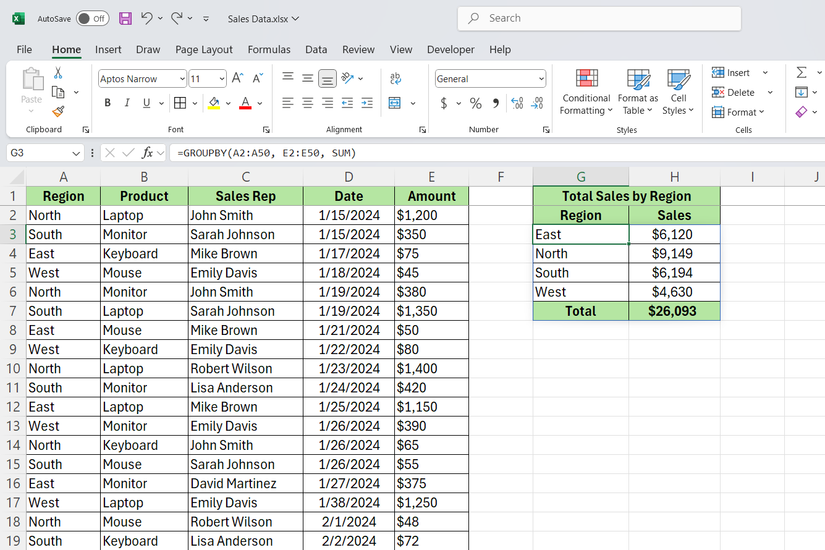
اگر می خواهید فروش توسط منطقه و محصول را خراب کنید ، می توانید چندین ستون را به پارامتر row_fields منتقل کنید:
= Groupby (A2: B50 ، E2: E50 ، جمع)
این یک گروه بندی تو در تو ایجاد می کند که در آن هر منطقه توسط محصول شکسته می شود و به شما نمایش مفصلی در مورد اینکه درآمد شما از کجا می آید ، می دهد.
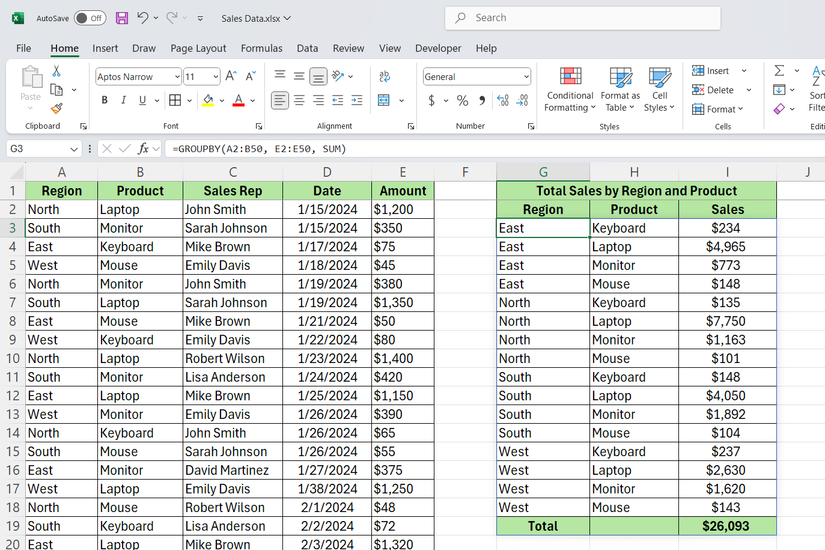
هر زمان که داده منبع شما تغییر می کند ، خروجی به طور خودکار به روز می شود. شما نیازی به تازه کردن یا محاسبه دستی ندارید – فرمول همیشه داده های فعلی شما را منعکس می کند.
یکی از مزیت های Groupby نسبت به جداول محوری ، توانایی آن در جمع آوری متن است ، نه فقط اعداد. اگر می خواهید تمام نمایندگان فروش ذکر شده برای هر منطقه را به عنوان یک لیست جدا از کاما مشاهده کنید ، می توانید از TextJoin به عنوان پارامتر عملکرد خود استفاده کنید.
به عنوان مثال ، گروه های فرمول زیر بر اساس منطقه و کلیه نام های فروش در هر گروه را به هم می پیوندند.
= Groupby (A2: A50 ، C2: C50 ، Lambda (x ، textjoin (“،” ، true ، x))
جداول محوری نمی توانند این کار را انجام دهند – آنها محدود به شمارش یا نشان دادن مقادیر متن فردی هستند ، نه اینکه آنها را در یک خروجی واحد ترکیب کنند.
Pivotby یک طرح محوری آشنا را بدون دردسر ایجاد می کند
بله ، یک میز کلاسیک دو طرفه با یک فرمول واحد
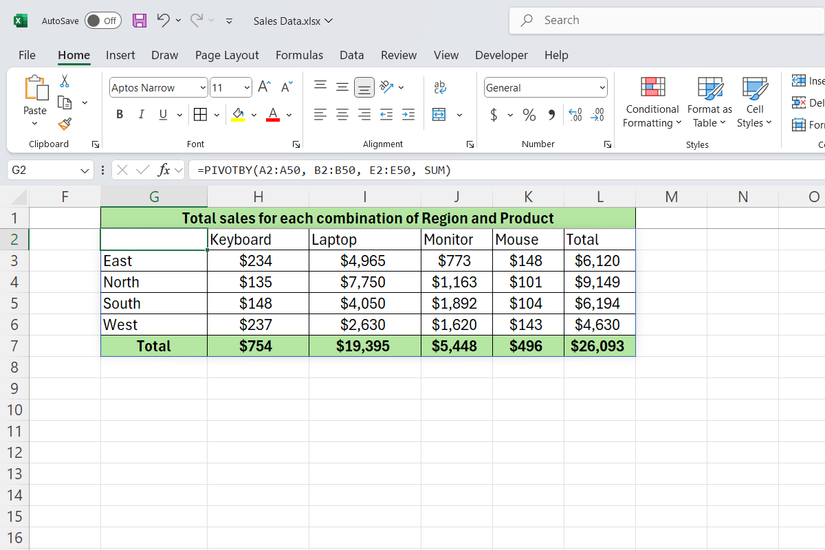
Pivotby با ایجاد خلاصه دو بعدی-روسرها و ستون هایی که با هم کار می کنند ، جمع آوری داده ها را یک قدم جلوتر می برد. تفاوت این است که شما به جای کلیک بر روی کادرهای گفتگو ، فرمول را می نویسید.
این عملکرد هنگامی مفید است که شما باید ببینید که چگونه دو دسته از یکدیگر تقاطع می کنند. به عنوان مثال ، اگر می خواهید فروش را بر اساس منطقه در محصولات مختلف مشاهده کنید ، Pivotby همه چیز را با فرمت شبکه ای ترتیب می دهد که اسکن آن آسان است.
این نحو طولانی با چندین پارامتر اختیاری دارد:
= Pivotby (row_fields ، col_fields ، مقادیر ، عملکرد ، [field_headers] ، [row_total_depth] ، [row_sort_order] ، [col_total_depth] ، [col_sort_order] ، [filter_array] ، [neatal_to])
پارامترها مانند این کار می کنند:
- row_fields: ستون یا ستون هایی که ردیف های شما را تعریف می کنند. این همان چیزی است که در سمت چپ جدول خروجی شما ظاهر می شود. می توانید از یک ستون یا ستون های مختلف برای گروه بندی ردیف های تو در تو استفاده کنید.
- col_fields: ستون یا ستون هایی که ستون های شما را تعریف می کنند. این مقادیر در بالای جدول خروجی شما ظاهر می شوند و بعد افقی خلاصه شما را ایجاد می کنند.
- مقادیر: داده هایی که جمع می کنید. این به طور معمول یک ستون عددی است که می خواهید برای هر ترکیبی از مقادیر ردیف و ستون جمع آوری ، متوسط یا حساب کنید.
- عملکرد: محاسبه برای استفاده از هر تقاطع گروههای ردیف و ستون. گزینه های مشترک شامل جمع ، میانگین ، تعداد ، حداکثر و حداقل است.
موارد زیر پارامترهای اختیاری هستند:
- Field_Headers: 1 را تنظیم کنید تا هدرها را در خروجی یا 0 قرار دهید تا آنها را حذف کنید. اگر این موضوع را از بین ببرید ، اکسل به طور پیش فرض عنوان را شامل می شود.
- row_total_depth: کنترل می کند که آیا جمع آوری ردیف و زیرنویس را اضافه کنید. برای جمع آوری های بزرگ ، 2 برای زیر مجموعه ها و جمع های بزرگ و غیره روی 1 تنظیم کنید.
- row_sort_order: نحوه طبقه بندی گروه های ردیف در خروجی را تعیین می کند. از 1 برای سفارش صعودی ، -1 برای سفارش نزولی استفاده کنید ، یا آن را حذف کنید تا ترتیب اصلی را از داده های منبع خود حفظ کنید.
- col_total_depth: همان row_total_depth ، اما برای کل ستون. این ستون های خلاصه را در سمت راست خروجی شما اضافه می کند.
- col_sort_order: مرتب سازی گروه های ستون در جدول خروجی شما را کنترل می کند. از 1 برای صعود ، -1 برای نزولی استفاده کنید ، یا آن را برای حفظ دنباله اصلی رها کنید.
- Filter_Array: یک آرایه واقعی/نادرست که تعیین می کند کدام ردیف از داده های منبع شما باید در محاسبه محوری گنجانده شود.
- Neatal_TO: نحوه محاسبه کل و درصد در هنگام استفاده از توابع خاص تجمع را تغییر می دهد. برای کل استاندارد روی 0 (یا حذف) تنظیم کنید. برای محاسبه مقادیر به عنوان درصدی از کل ردیف ، یا 2 برای درصد کل ستون ها روی 1 تنظیم کنید.
با استفاده از صفحه گسترده داده های فروش ، فرض کنید می خواهید کل فروش را برای هر ترکیبی از منطقه و محصول ببینید. شما می نویسید:
= Pivotby (A2: A50 ، B2: B50 ، E2: E50 ، جمع)
این گروه به صورت منطقه (ستون A) ردیف می کند ، ستون هایی را برای هر محصول (ستون B) ایجاد می کند و مقادیر مقدار (ستون E) را برای هر تقاطع خلاصه می کند. خروجی شبکه ای است که دقیقاً نشان می دهد که هر محصول در هر منطقه چه مقدار فروخته می شود. و فرمول با تغییر داده های شما به طور خودکار به روز می شود.
این توابع پویا ، شفاف و ادغام آسان تر هستند
هر دو Groupby و Pivotby ، با فرمول ، با بقیه صفحه گسترده خود بازی می کنند. شما می توانید خروجی آنها را در محاسبات دیگر ارجاع دهید ، در صورت بیانیه ها آنها را بپیچید ، یا آنها را با فیلتر ترکیب کنید تا خلاصه های مشروط ایجاد شود.
شفافیت یک مزیت بزرگتر از آنچه به نظر می رسد است. وقتی شخصی صفحه گسترده شما را باز می کند ، می تواند روی سلول کلیک کند و دقیقاً ببیند که چگونه خلاصه ساخته شده است.
هیچ ذخیره سازی میز محوری پنهان یا تنظیمات میدانی برای رمزگشایی وجود ندارد ، همکاری را آسان تر کرده و کاهش “چگونه این شماره را دریافت کردید؟” سوالات. شما می توانید داشبورد بسازید که به خودی خود به روز می شوند. این نوع گردش کار برای تنظیم با جداول محوری پیچیده تر است که نیاز به تازه کردن دستی دارند.