وقتی صحبت از تجزیه و تحلیل داده ها می شود ، جداول محوری بسیار مفید است و بسیاری از افراد PRO برای آنها کوپه می کنند. با این حال ، آنها هنگام تغییر داده ها به طور خودکار به روز نمی شوند و آن کار آسان را برای کاربر قرار می دهند. خوشبختانه ، اکسل عملکرد Groupby را دارد ، که به من امکان می دهد چیزی را از نظر ساختاری شبیه به یک جدول محوری اما با قابلیت های پویا ایجاد کنم.
وقتی صحبت از تجزیه و تحلیل داده ها می شود ، جداول محوری بسیار مفید است و بسیاری از افراد PRO برای آنها کوپه می کنند. با این حال ، آنها هنگام تغییر داده ها به طور خودکار به روز نمی شوند و آن کار آسان را برای کاربر قرار می دهند. خوشبختانه ، اکسل عملکرد Groupby را دارد ، که به من امکان می دهد چیزی را از نظر ساختاری شبیه به یک جدول محوری اما با قابلیت های پویا ایجاد کنم.
جداول محوری به راحتی ایجاد می شود ، زیرا فقط با چند کلیک می توانید این کار را انجام دهید. اما من به شما اطمینان می دهم که استفاده از فرمول Groupby برای تجزیه و تحلیل داده های شما چندان سخت نیست – حتی می تواند نحوه نوشتن فرمول ها را از این پس تغییر دهد. علاوه بر این ، شما می توانید با استفاده از یک راه حل مرتب ، از فرمول های Groupby با برش استفاده کنید تا فوراً آنها را در صورت لزوم فیلتر کنید.
نحوه استفاده از عملکرد Groupby در یک فرمول
یک جایگزین عالی برای میزهای محوری
Groupby یک تابع اکسل است که به شما امکان می دهد ردیف ها را بر اساس یک یا چند ستون گروه بندی کنید و سپس آنها را با استفاده از توابع دیگر جمع کنید. این یک عملکرد آرایه پویا است ، به این معنی که محاسبات را روی سلول های مختلف انجام می دهد و یک نتیجه واحد یا نتایج متعدد را برمی گرداند. در اکسل 365 معرفی شد ، به این معنی که در اکسل 2019 یا بالاتر در دسترس نیست.
در اینجا نحو عملکرد Groupby با پارامترهای مورد نیاز آورده شده است:
=GROUPBY(row_fields, values, function)
پارامتر row_fields دسته یا ستونی را برای گروه بندی داده های خود (به عنوان مثال ، تاریخ ، ماه ، فروش یا بخش) مشخص می کند. پارامتر مقادیر محدوده با مقادیری است که می خواهید جمع کنید. سرانجام ، پارامتر عملکرد ، عملکردی است که مقادیر را جمع می کند (به عنوان مثال ، جمع ، میانگین و تعداد).
اگر نمی توانید عملکرد مناسب جمع آوری را برای Groupby پیدا کنید ، می توانید به جای آن یک تابع Lambda سفارشی ایجاد کنید.
حال فرض کنید من یک جدول با داده های فروش دارم و می خواهم کل فروش هر کارمند را تعیین کنم. در اینجا آنچه به نظر می رسد این فرمول است (توجه داشته باشید که من همچنین هدرهای موجود در عملکرد را شامل می شوم):
=GROUPBY(Table1[[#All],[Salesperson]], Table1[[#All],[Sales]], SUM)
در اصل ، فرمول آرایه ای را ایجاد می کند که هر فروشنده و کل فروش آنها را لیست می کند. من به ترتیب ستون های فروش و فروش را برای پارامترهای Row_Fields و مقادیر انتخاب کردم. برای پارامتر عملکرد ، از جمع استفاده کردم.
من به راحتی می توانم با یک جدول محوری با کشیدن قسمت فروشنده به ردیف ها و قسمت فروش به مقادیر ، نتیجه مشابهی را بدست آورم. همچنین به زیبایی فرمت خواهد شد. با این حال ، اگر من در جدول نمونه هر چیزی را تغییر دهم ، عملکرد Groupby به طور خودکار جدول برگشتی را به روز می کند.
می توانید بیش از یک ستون را برای پارامتر row_fields در عملکرد Groupby انتخاب کنید ، اما آنها به ترتیب ظاهر شده در جدول ظاهر می شوند. برای سفارش آنها به هر حال که می خواهید ، می توانید از عملکرد HSTACK استفاده کنید.
=GROUPBY(HSTACK(Table1[[#All],[Salesperson]], Table1[[#All],[Region]]), Table1[[#All],[Sales]], SUM)
در مورد آن پارامترهای اختیاری
از عملکرد Groupby کامل استفاده کنید
عملکرد اصلی Groupby به خوبی کار می کند ، اما من به سرعت فهمیدم که آن پارامترهای اختیاری می توانند چیزهای بیشتری را ادویه کنند.
=GROUPBY(row_fields, values, function, [field_headers], [total_depth], [sort_order], [filter_array], [field_relationship])
در اینجا آنچه هر پارامتر انجام می دهد آورده شده است:
- FIELD_HEADERS: به شما امکان می دهد مشخص کنید که آیا هدرها باید نمایش داده شوند یا خیر. مقدار از دست رفته (پیش فرض) = اتوماتیک ، 0 = نه ، 1 = بله اما نشان نمی دهد ، 2 = نه ، تولید می شود ، و 3 = بله و نشان می دهد.
- Total_Depth: به شما امکان می دهد تا مشخص کنید که آیا زیرنویس ها و جمع های بزرگ را نشان می دهید. مقدار از دست رفته (پیش فرض) = جمع های بزرگ و در صورت امکان ، زیرنویس ، 0 = بدون کل ، 1 = تعداد بزرگ ، 2 = جمع بزرگ و زیرنویس ، -1 = جمع های بزرگ در بالا ، و -2 = تعداد عالی و زیرنویس در بالا.
- SORT_ORDER: این پارامتر به شما امکان می دهد تا چگونه نتایج خود را مرتب کنید. به عنوان مثال ، اگر می خواهید ستون چهارم جدول را به ترتیب صعودی مرتب کنید ، وارد می شوید.
- filter_array: این به شما امکان می دهد تا نتایج را فیلتر کنید و فقط ردیف هایی را نشان می دهد که معیارهای مشخص شده را برآورده می کنند.
- field_relationship: نحوه گروه بندی داده ها را هنگام وارد کردن چندین ستون در پارامتر row_fields ، با 0 (پیش فرض) = سلسله مراتب و 1 = جدول مشخص می کند.
در اینجا نمونه ای از فرمول کامل در عمل آورده شده است:
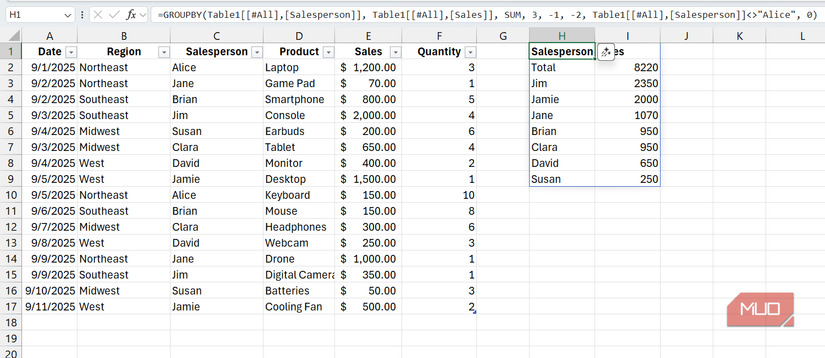
=GROUPBY(Table1[[#All],[Salesperson]], Table1[[#All],[Sales]], SUM, 3, -1, -2, Table1[[#All],[Salesperson]]<>"Alice", 0)
پارامتر field_headers تنظیم شده است تا هدرها را نشان دهد ، در حالی که پارامتر total_depth مجموعه های بزرگ را در بالا نشان می دهد. پارامتر sort_order نتایج را بر اساس ستون دوم (فروش) به ترتیب نزولی مرتب می کند. پارامتر Filter_Array از منطق شرطی برای نمایش فقط آنهایی که نام آنها (ستون فروشنده) آلیس نیست ، استفاده می کند.
با استفاده از برش با عملکرد Groupby
داده ها را با کلیک یک دکمه مرتب کنید
نکته ای که میزهای محوری را بسیار عالی می کند این است که آنها با برش کار می کنند. برش ها همچنین می توانند با عملکرد Groupby کار کنند ، اما برای تسهیل فیلتر به یک ستون یاور نیاز دارند.
از آنجا که برش ها با جداول کار می کنند ، ابتدا باید اطمینان حاصل کنم که داده ها در قالب جدول قرار دارند. سپس ، من ستونی را ایجاد کردم که به عنوان فیلتر خدمت می کند (من آن را فیلتر نامگذاری کردم ، اما می توانید آن را هر چیزی بنامید). از آنجا ، من از عملکرد زیرنویس استفاده می کنم تا به من کمک کنم تعیین کنم که یک ردیف خالی است یا خیر.
=SUBTOTAL(103, [@Salesperson])
من عملکرد COUNTA (103) را انتخاب کردم تا با زیرنویس استفاده کنم زیرا ردیف های پنهان را نادیده می گیرد – اگر سلول ارجاع شده غیر خالی و قابل مشاهده باشد ، 1 باز می گردد و اگر پنهان یا خالی باشد. من از ستون فروش به عنوان مقدار مرجع استفاده کردم زیرا می دانم که هرگز خالی یا پنهان نخواهد بود. هنگامی که من در اولین سلول ستون فیلتر وارد این فرمول شدم ، از آنجا که این یک جدول است ، به طور خودکار به بقیه سلول ها اضافه شد.
سپس با استفاده از ستون فروش یک برش ایجاد کردم و آن را به یک ورق جداگانه منتقل کردم. پس از آن ، من ستون فیلتر را در پارامتر filter_array عملکرد Groupby وارد کردم تا بتواند با برش کار کند.
=GROUPBY(Table1[[#All],[Salesperson]], Table1[[#All],[Sales]], SUM, 3, , , Table1[[#All],[Filter]])
اکنون من از برش برای فیلتر کردن آرایه حاصل از عملکرد Groupby استفاده می کنم. به خاطر داشته باشید که جدول منبع را نیز فیلتر می کند.
فرمول های Groupby جایگزینی برای میزهای محوری نیستند
Groupby جایگزینی برای جداول محوری است ، نه جایگزینی عمده فروشی-در صورت نیاز به تجمع پویا و مبتنی بر فرمول ، از آن استفاده کنید. علاوه بر این ، کنترل بیشتری را از طریق فرمول ها فراهم می کند و شفاف تر و ویرایش تر است. تعامل ، راحتی و کارآیی جداول محوری را از دست خواهم داد ، اما به نظر می رسد فرمول های Groupby قادر به رسیدگی به نیازهای تجزیه و تحلیل داده های من هستند.