
بعد از سالها کشتی گیری با صفحات گسترده کثیف ، من چهار کارکرد اکسل را کشف کردم که هر هفته با خودکار کردن کارهای خسته کننده اکثر مردم به صورت دستی ، ساعت ها را نجات می دهم.
بعد از سالها کشتی گیری با صفحات گسترده کثیف ، من چهار کارکرد اکسل را کشف کردم که هر هفته با خودکار کردن کارهای خسته کننده اکثر مردم به صورت دستی ، ساعت ها را نجات می دهم.
4
Xlookup
Vlookup را منسوخ می کند
من سالها پیش وقتی Xlookup را کشف کردم ، استفاده از VLookup را متوقف کردم. در حالی که Vlookup فقط به سمت راست جستجو می کند و هنگام حرکت ستون ها می شکند ، Xlookup از هر جهت کار می کند و انعطاف پذیر می ماند. XLOOKUP یکی از توابع اکسل است که می تواند در زمان یافتن داده های خاص در صفحه گسترده شما باعث صرفه جویی در وقت شما شود.
در داده های قیمت گذاری مؤلفه رایانه من ، باید قیمت های GPU خاص را بر اساس مدل های محصول پیدا کنم. با Vlookup ، باید کل جدول خود را بازسازی کنم. اما با xlookup ، من فقط می نویسم:
= Xlookup (“Gigabyte Geforce RTX 3060 12GB Gaming OC” ، C: C ، D: D)
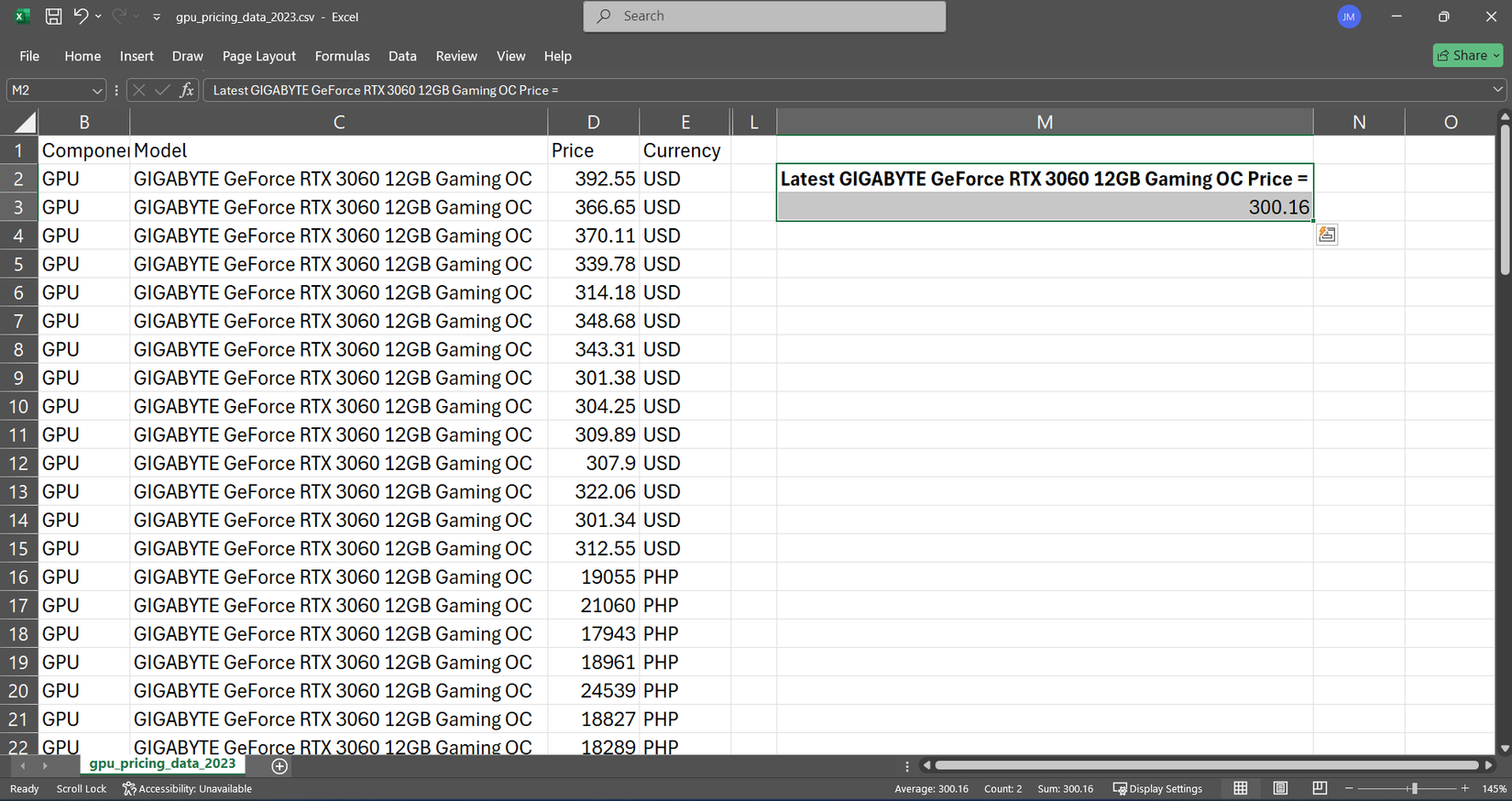
Xlookup کل ستون محصول را جستجو می کند ، GPU من را می یابد و قیمت مربوطه را برمی گرداند. اهمیتی نمی دهد که ستون قیمت در کجا قرار دارد ، و اگر بعداً ستون های بیشتری اضافه کنم ، شکسته نمی شود. من از این دائماً برای اطلاعات مربوط به محصول مرجع بین برگه های مختلف استفاده می کنم بدون اینکه چیزی را اصلاح کنم.
نحو اساسی برای Xlookup:
= xlookup (lookup_value ، lookup_array ، return_array)
- lookup_value: مقداری که می خواهید پیدا کنید.
- lookup_array: از کجا می توان مقدار را جستجو کرد.
- Return_array: ستون یا ردیفی که دارای مقدار مورد نظر شما است.
بنابراین ، در مورد من ، ارزشی که می خواستم پیدا کنم “Gigabyte GeForce RTX 3060 12GB Gaming OC” بود. من می خواستم آن مقدار را در ستون C: C جستجو کنم و مقدار مربوطه را از D: D در همان ردیف که مسابقه پیدا شده است برگردانم.
نکته دیگری که من در مورد Xlookup دوست دارم این است که اگر در پایان فرمول “، -1” اضافه کنم ، از پایین به بالا جستجو می کند و به من اجازه می دهد جدیدترین قیمت را به طور خودکار پیدا کنم. این باعث می شود هر بار که صفحات گسترده خود را به روز می کنم ، از مرتب سازی دستی داده ها را نجات دهم.
3
sumifs و countifs
معیارهای مختلفی مانند یک حرفه ای را کنترل کنید
عملکردهای اصلی و شمارش برای چیزهای ساده خوب است ، اما وقتی به تجزیه و تحلیل واقعی نیاز دارید ، کم می شوند. هنگامی که من نیاز به تجزیه و تحلیل داده های قیمت گذاری خود در شرایط مختلف دارم ، Sumifs و Countif توابعی هستند که من معمولاً از آنها استفاده می کنم. این توابع به من اجازه می دهد صدها ردیف را به راحتی برش دهم.
بیایید بگوییم که می خواهم تعداد پردازنده های AMD را در آمازون ایالات متحده در دسترس داشته باشم. به جای فیلتر دستی ، می نویسم:
= Countifs (F: F ، “Amazon Us” ، K: K ، “AMD”)
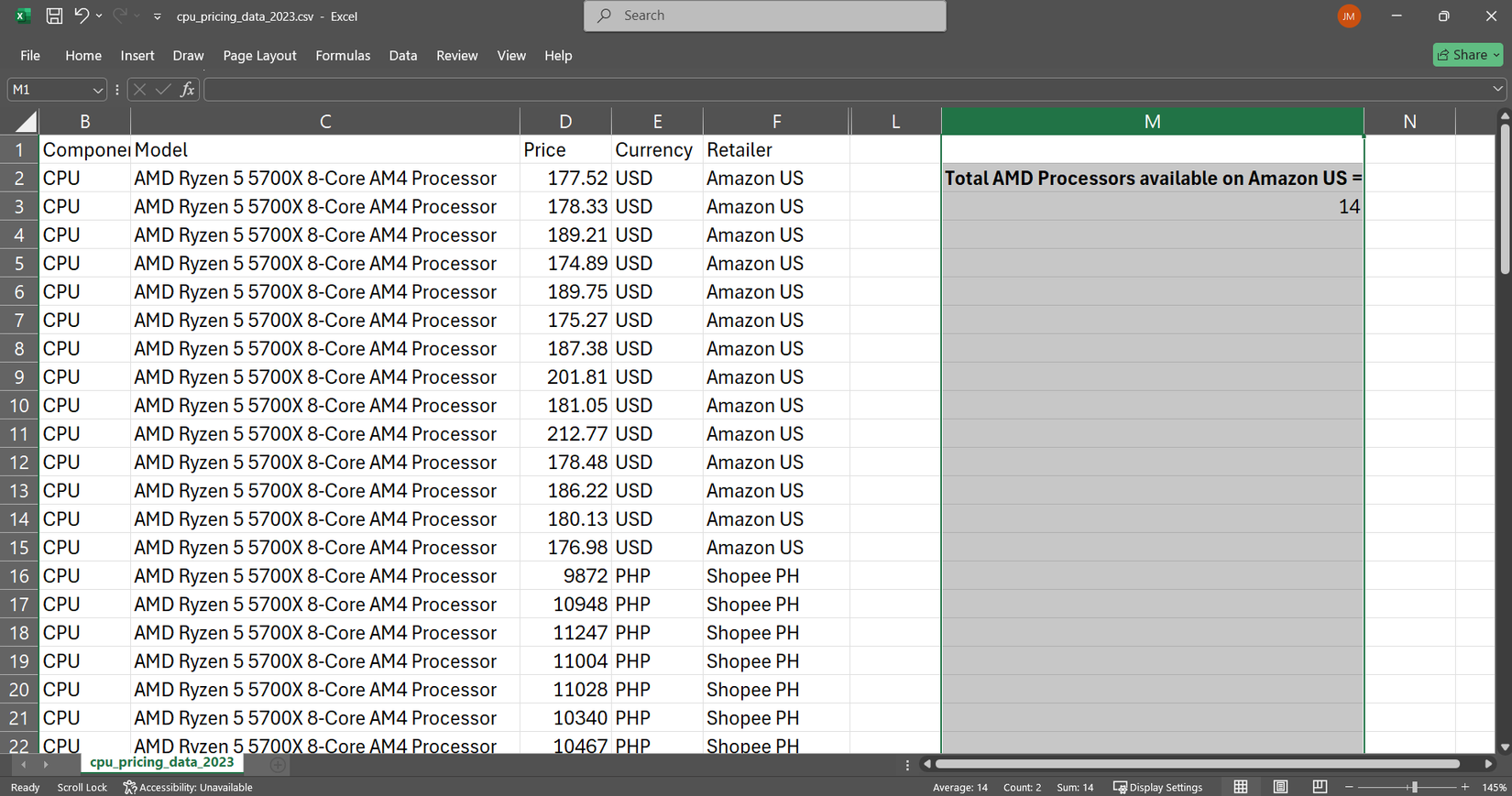
این فوراً به من می گوید 14 پردازنده AMD در آمازون در مجموعه داده های من ذکر شده است. زیبایی در اینجا این است که من می توانم به همان اندازه معیارهای مورد نیاز خود را جمع کنم.
برای تجزیه و تحلیل قیمت ، SUMIFS به همان روش کار می کند. برای محاسبه ارزش کل کلیه پردازنده های اینتل که در حال حاضر موجود است ، استفاده می کنم:
= sumifs (d: d ، k: k ، “intel” ، g: g ، “در سهام”)
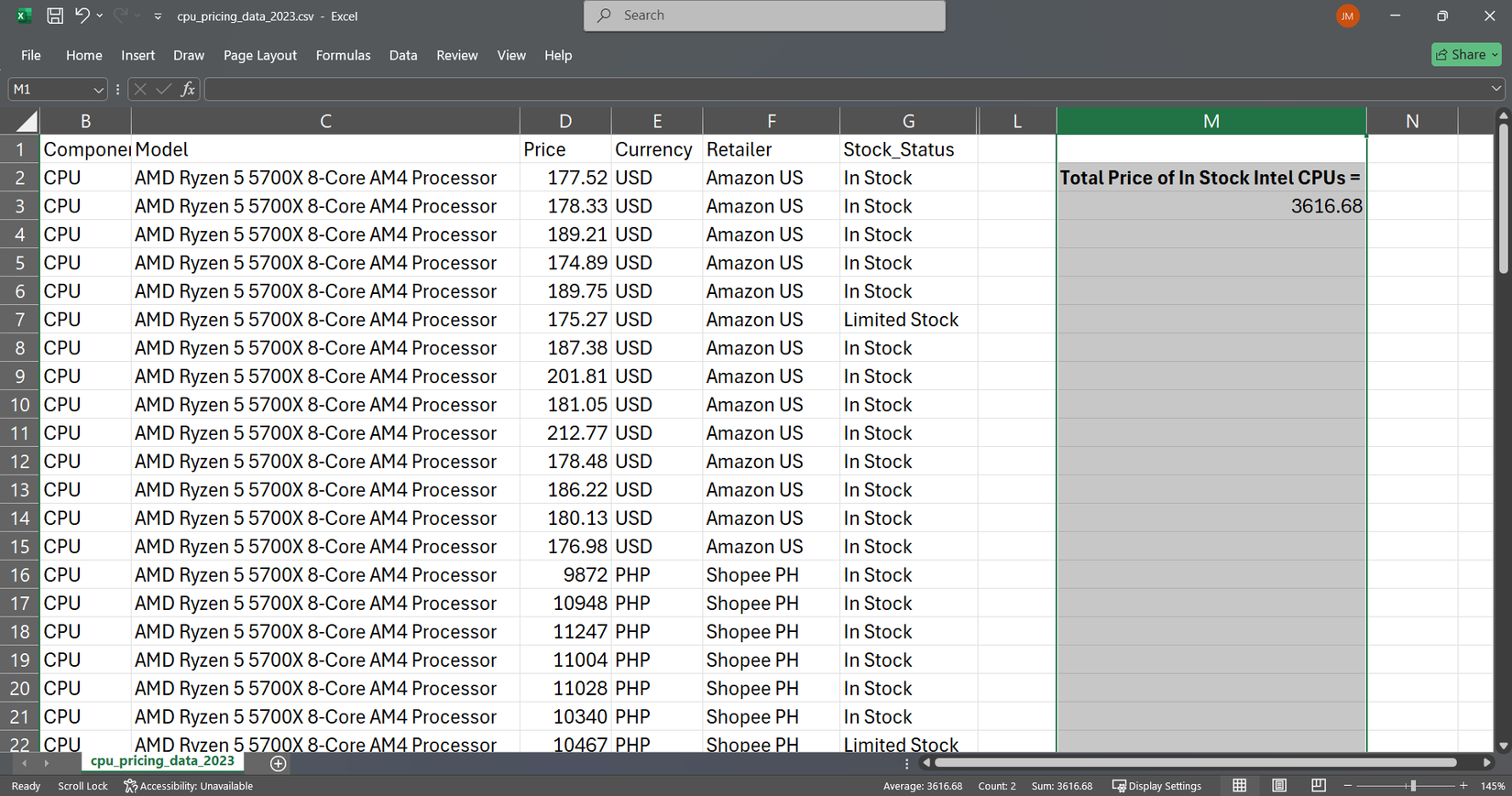
این خلاصه تمام قیمت ها در ستون D است که در آن برند برابر با “Intel” و وضعیت سهام برابر با “در سهام” است.
نحو برای sumifs:
= sumifs (sum_range ، معیارها_range1 ، معیارها 1 ، معیارها_RANGE2 ، معیارهای 2 …)
- sum_range: ستونی که می خواهید اضافه کنید.
- معیارها_RANGE1: اولین ستون برای بررسی شرایط در برابر.
- معیارها 1: شرط برای برد اول.
- معیارها_RANGE2 ، معیارهای 2: دامنه ها و شرایط اضافی (اختیاری).
Countifs به طور یکسان کار می کند ، به جز اینکه به جای جمع بندی مقادیر ، ردیف های تطبیق را شمارش می کند:
= Countifs (معیارها_RANGE1 ، معیارها 1 ، معیار_ Range2 ، معیارها 2 …)
من Sumifs و Countifs را برای گزارش های سریع ترجیح می دهم زیرا آنها فوراً با داده های جدید به روز می شوند ، به طور مرتب در فرمول های موجود من قرار می گیرند و به من اجازه می دهم همه چیز را بدون تنظیم یک جدول محوری جداگانه نگه دارم.
2
تمیز و تمیز
شما را از داده های جهنم ذخیره کنید
هیچ چیز یک صفحه گسترده را سریعتر از داده های کثیف با فضاهای اضافی و شخصیت های نامرئی خراب نمی کند. من این روش سخت را آموختم که جستجوی من به دلیل عدم وجود فضاهای در نام مدل ، ناکام ماند.
تریم فضاهای اضافی را از ابتدا و انتهای متن از بین می برد ، به علاوه هر فضای اضافی بین کلمات. وقتی داده ها را از منابع مختلف وارد می کنم ، نام محصولات اغلب با فاصله متناقض همراه است. به جای تمیز کردن دستی هر سلول ، یک ستون یاور ایجاد می کنم و از آن استفاده می کنم:
= تریم (C2)
سپس ماوس خود را در لبه سلول معلق می کنم تا زمانی که به نماد Plus (+) تبدیل شود ، سپس آن را به تمام ردیف هایی که می خواهم عملکرد تر و تمیز کار کند ، بکشید.
- تصویر توسط Jayric Maning -بدون ویژگی های لازم
- تصویر توسط Jayric Maning -بدون ویژگی های لازم
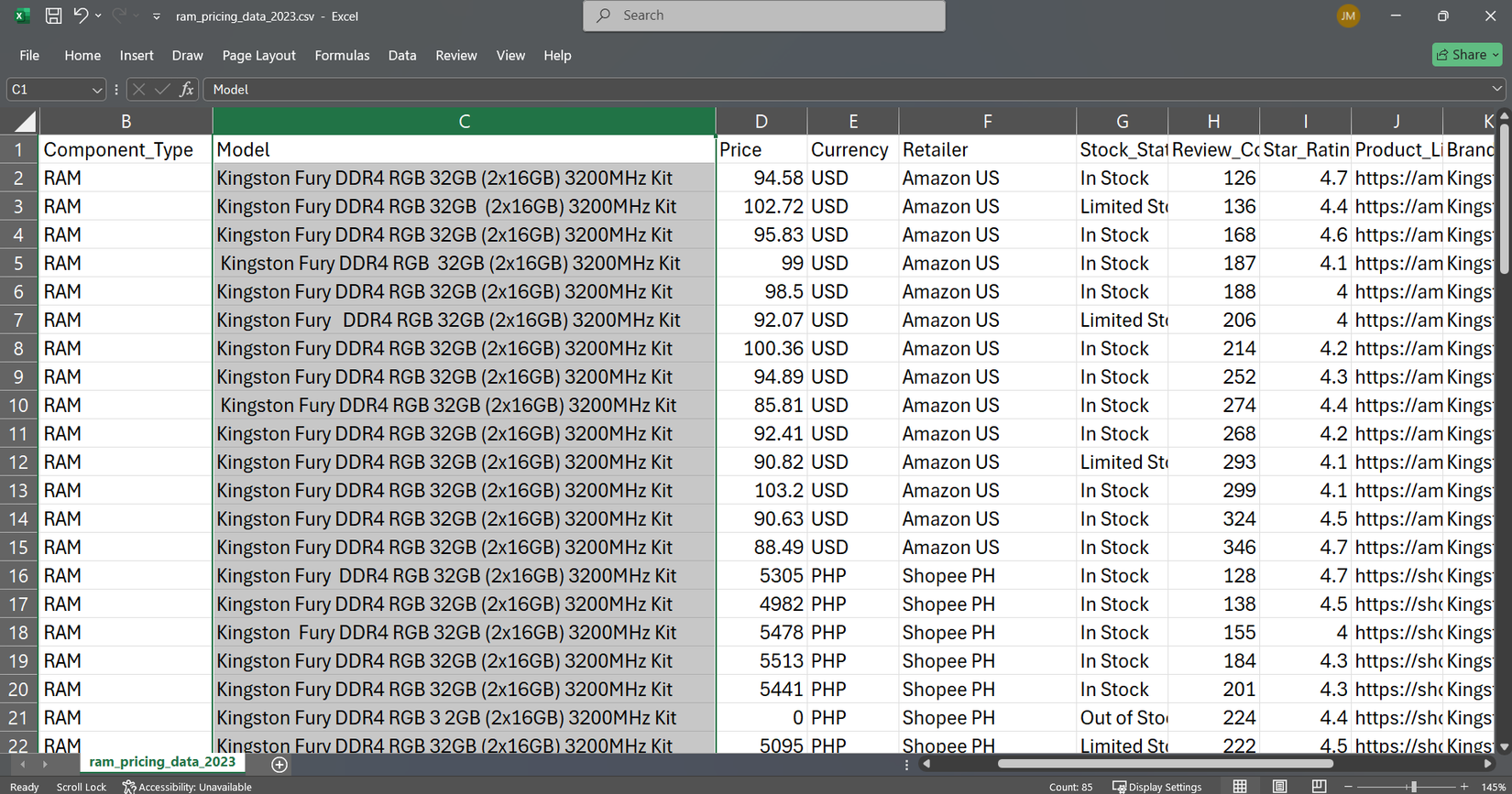
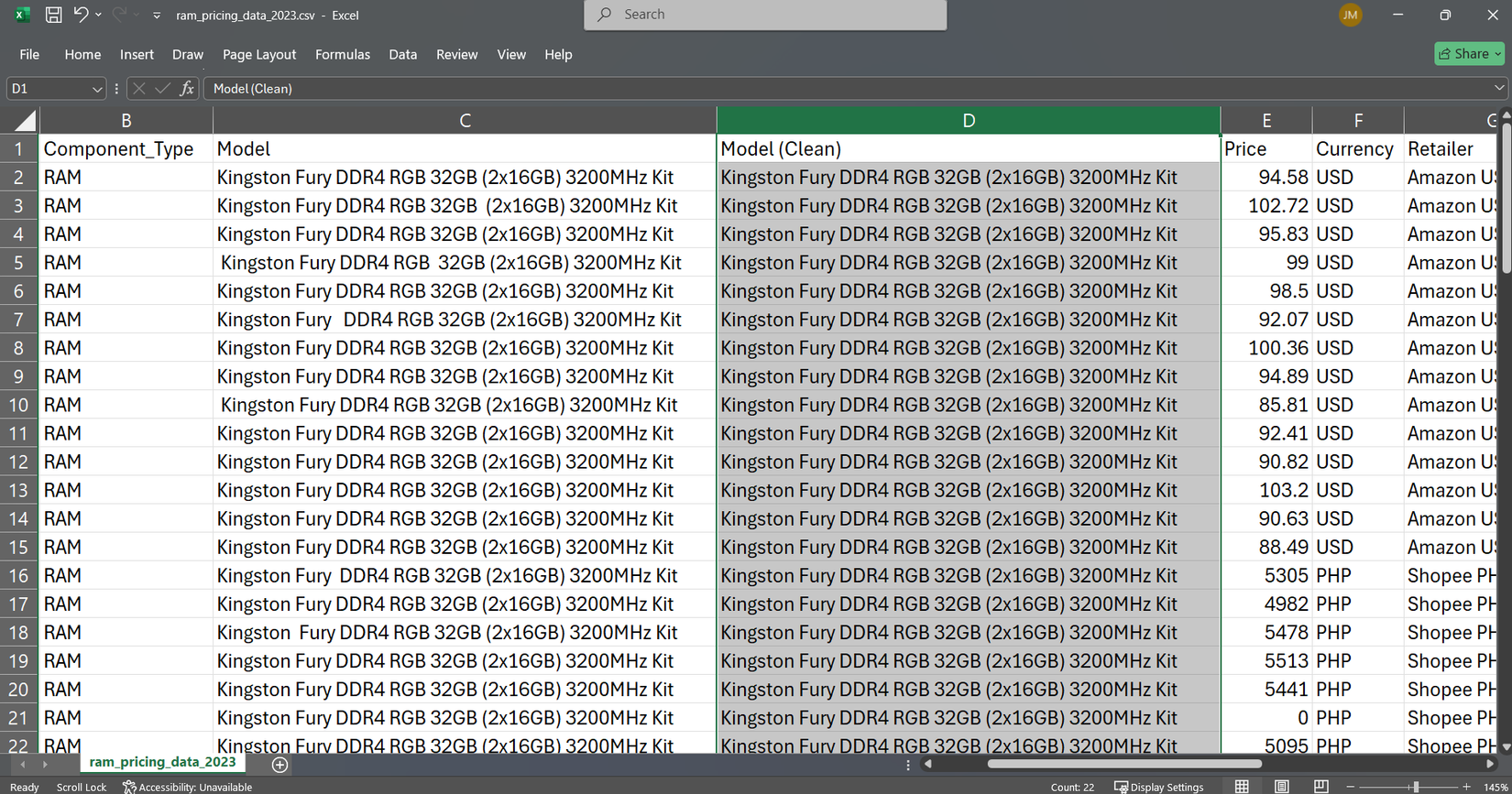
این “Kingston Fury DDR4 RGB 32GB” به “Kingston Fury DDR4 RGB 32GB” تبدیل می شود. تریم یک فضای بین کلمات را حفظ می کند اما همه چیز را از بین می برد.
پاک با از بین بردن شخصیت های غیر قابل چاپ که حتی نمی توانید آن را ببینید ، عمیق تر می شود. این گریملین های نامرئی اغلب در هنگام صادرات داده ها دزدگیر می شوند و باعث خرابی فرمول مرموز می شوند. من معمولاً هر دو عملکرد را با هم ترکیب می کنم:
= تریم (تمیز (C2))
نحو ساده است:
= تریم (متن): فضاهای اضافی را حذف می کند = تمیز (متن): شخصیت های غیر قابل چاپ را حذف می کند
بعد از تمیز کردن داده های من از این طریق ، عملکردهای Xlookup من هر بار کاملاً کار می کنند. در حالی که من از استفاده از پرس و جو برای تمیز کردن و تهیه کتابهای کاری خود استفاده می کنم ، اغلب می فهمم که عملکردهای تمیز و تمیز برای صفحات گسترده ساده که نیاز به تمیز کردن دارند ، به خوبی کار می کنند. با استفاده از این ابزارها ، من ساعت ها اشکال زدایی را با ساخت تمیز کردن داده ها یک قدم اول استاندارد در هر پروژه صفحه گسترده جدید ذخیره کرده ام.
1
TextBefore و TextAfter
دقیقاً آنچه را که شما نیاز دارید استخراج کنید
TextBefore و TextAfter چند مورد دیگر از عملکردهای مورد علاقه من اکسل برای تمیز کردن صفحات گسترده کثیف هستند. توابع متن جدید اکسل در کشیدن اطلاعات خاص از رشته های کثیف برتری دارد. ستون قیمت من دارای مدخل هایی مانند “177.52 دلار” ، “178.33 USD” ، “9055 ₱” و “9645.50 PHP” بود که همه با هم مخلوط شدند.
TextBefore همه چیز را قبل از تعیین کننده خاص استخراج می کند:
= TextBefore (D2 ، “USD”)
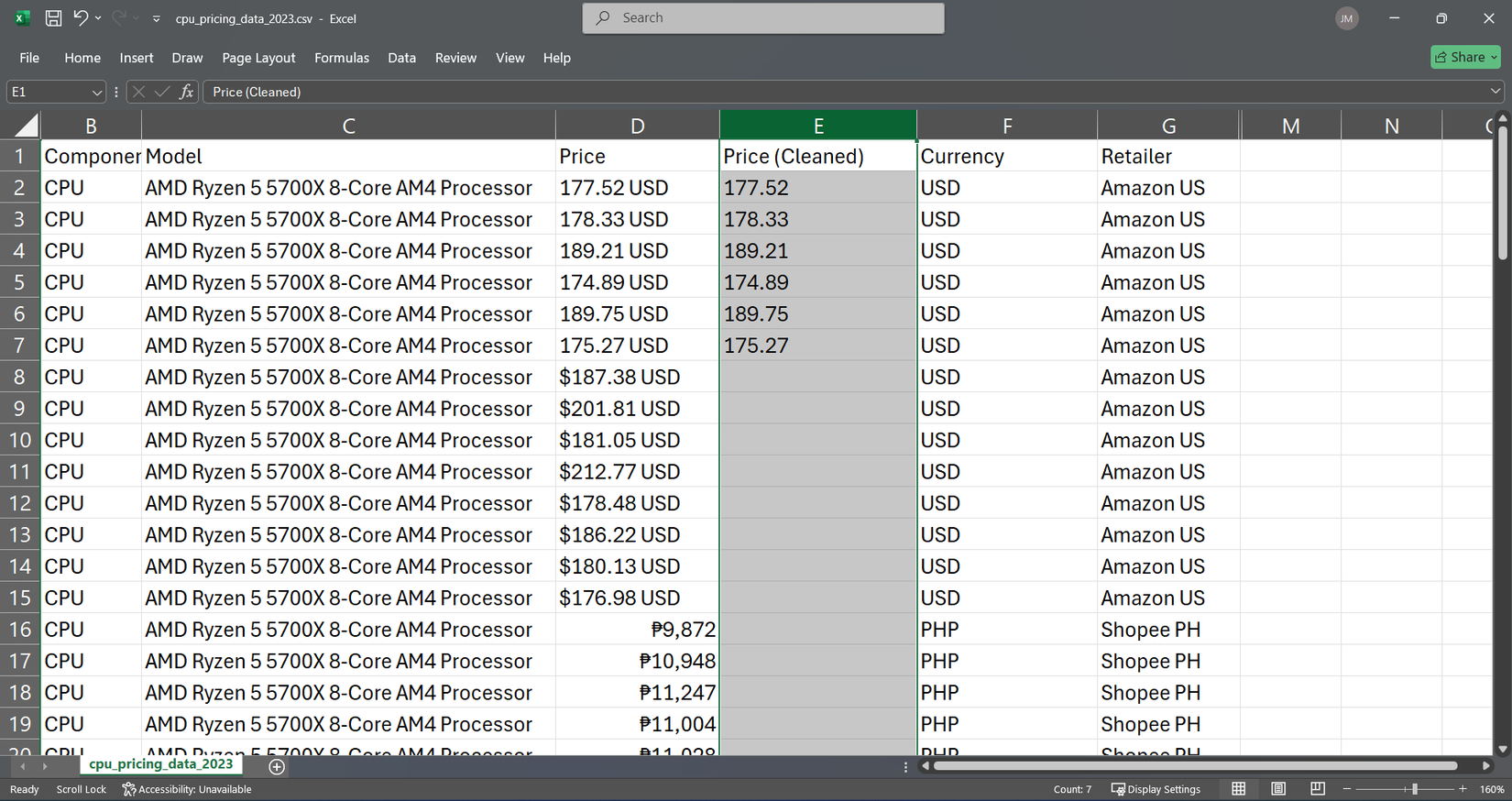
این فوراً “178.33” را از “178.33 USD” بیرون کشید.
TextAfter به صورت معکوس کار می کند و همه چیز را پس از تعیین کننده استخراج می کند:
= TextAfter (C2 ، “AMD”)
این پردازنده “Ryzen 5 5700x 8 Core AM4” از “پردازنده AMD Ryzen 5 5700x 8 Core AM4” استخراج شده است.
برای استخراج های پیچیده ، من هر دو عملکرد را با هم ترکیب می کنم. برای به دست آوردن فقط قیمت عددی از “177.52 $ USD”:
= TextBefore (TextAfter (D8 ، “$”) ، “USD”)
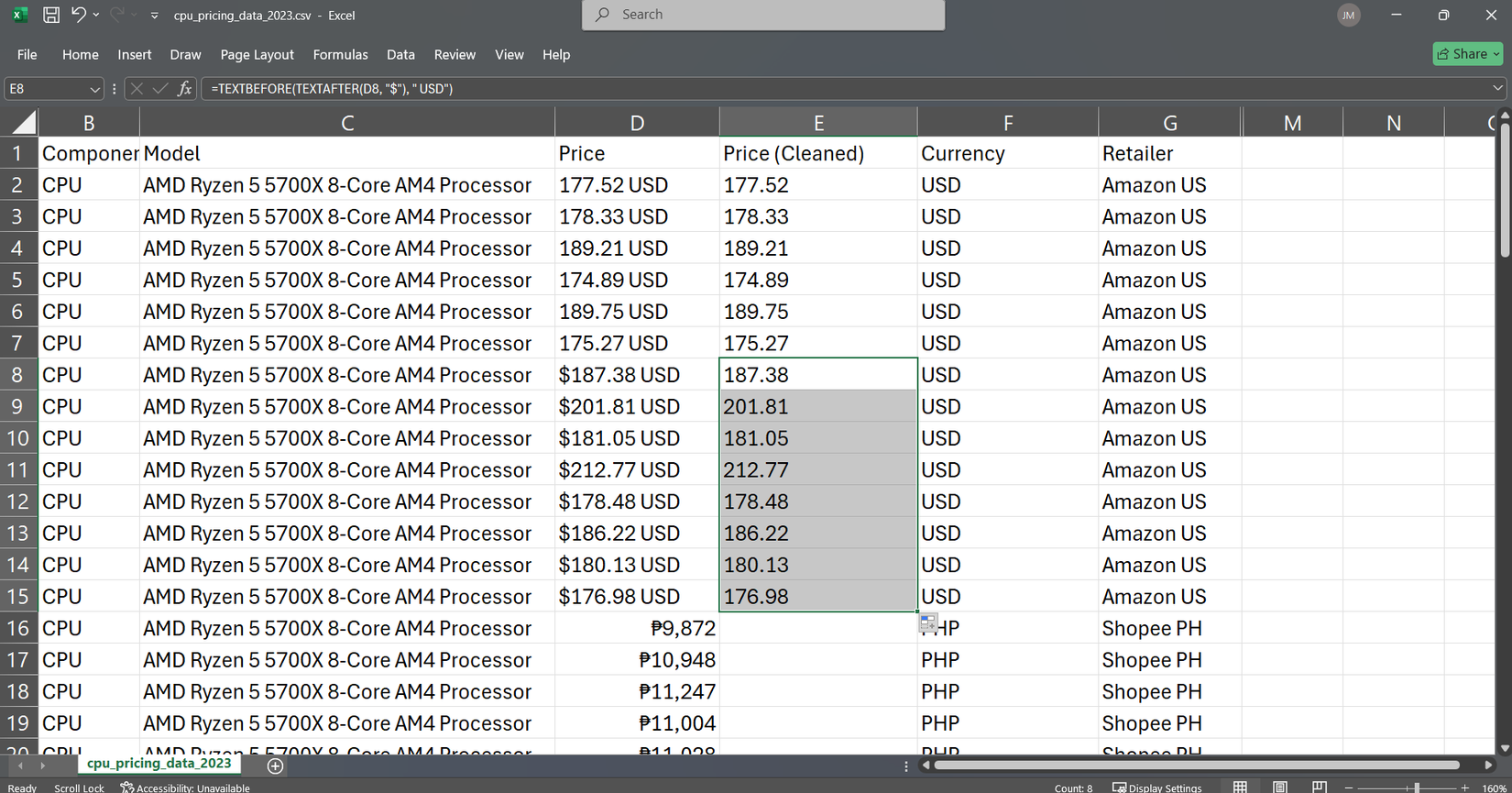
نحو برای TextBefore و TextAfter عبارتند از:
= TextBefore (متن ، تعیین کننده) و = TextAfter (متن ، تعیین کننده)
آنچه این کارکردها را انقلابی می کند ، دقت آنهاست. به جای استفاده از ترکیبات پیچیده Mid ، Find و LEN ، استخراج های تمیز با فرمول های ساده و قابل خواندن دریافت می کنم. من از این موارد دائما برای جدا کردن شماره های مدل ، استخراج مشخصات محصول و کشیدن داده های تمیز از متن وارداتی استفاده می کنم که در غیر این صورت به ساعات ویرایش دستی نیاز دارد.
این چهار کارکرد برخی از بزرگترین زمان های زمان در اکسل را حل می کند. یافتن داده ها با جستجوی انعطاف پذیر ، تجزیه و تحلیل با معیارهای متعدد ، تمیز کردن متن وارداتی کثیف و استخراج اطلاعات خاص از رشته های پیچیده. بیشتر افراد این کارها را به صورت دستی انجام می دهند و ساعت ها را صرف کار می کنند که با فرمول های مناسب چند دقیقه طول می کشد.
من از این توابع برای همه چیز استفاده کرده ام ، از تجزیه و تحلیل قیمت گذاری مؤلفه گرفته تا گزارش مدیریت موجودی. آنها بدون در نظر گرفتن صنعت شما کار می کنند زیرا داده های کثیف و نیازهای پیچیده جستجوی جهانی هستند. پس از تسلط بر آنها ، تعجب خواهید کرد که چگونه صفحه گسترده را بدون آنها مدیریت کرده اید.