بسیاری از ابزارهای هوش مصنوعی که ما از آن استفاده می کنیم در ابر اجرا می شود و به دسترسی به اینترنت نیاز دارند. و اگرچه می توانید از ابزارهای محلی AI نصب شده بر روی دستگاه خود استفاده کنید ، برای این کار به سخت افزار قدرتمندی نیاز دارید.
بسیاری از ابزارهای هوش مصنوعی که ما از آن استفاده می کنیم در ابر اجرا می شود و به دسترسی به اینترنت نیاز دارند. و اگرچه می توانید از ابزارهای محلی AI نصب شده بر روی دستگاه خود استفاده کنید ، برای این کار به سخت افزار قدرتمندی نیاز دارید.
حداقل ، این همان چیزی است که من فکر می کردم ، تا اینکه سعی کردم برخی از ابزارهای محلی AI را با استفاده از سخت افزار قدیمی قدیمی خود اجرا کنم-و دریافتم که در واقع کار می کند.
چرا به هر حال از یک چت بابات AI محلی استفاده می کنید؟
من از چت های بی شماری آنلاین AI مانند Chatgpt ، Gemini ، Claude و غیره استفاده کرده ام. آنها عالی کار می کنند. اما در مورد آن مواقعی که اتصال به اینترنت ندارید و هنوز هم می خواهید از AI Chatbot استفاده کنید ، چطور؟ یا اگر می خواهید با چیزی فوق العاده خصوصی یا اطلاعاتی کار کنید که نمی توان برای کار یا در غیر این صورت فاش کرد؟
این زمانی است که شما به یک مدل زبان محلی و آفلاین (LLM) نیاز دارید که تمام مکالمات و داده های شما را در دستگاه خود نگه می دارد.
حریم خصوصی یکی از اصلی ترین دلایل استفاده از LLM محلی است. اما دلایل دیگری نیز وجود دارد ، مانند اجتناب از سانسور ، استفاده آفلاین ، صرفه جویی در هزینه ، سفارشی سازی و غیره.
LLM های کمکی چیست؟
بزرگترین مسئله برای اکثر افرادی که می خواهند از LLM محلی استفاده کنند ، سخت افزار است. قدرتمندترین مدل های هوش مصنوعی نیاز به سخت افزار بسیار قدرتمند برای اجرای آن دارند. در خارج از راحتی ، محدودیت های سخت افزاری دلیل دیگری است که از بیشتر چت های AI در ابر استفاده می شود.
محدودیت های سخت افزاری یکی از دلایلی است که من معتقدم نمی توانم LLM محلی را اجرا کنم. من این روزها یک کامپیوتر متوسط دارم ، با یک پردازنده AMD Ryzen 5800X (راه اندازی 2020) ، 32 گیگابایت رم DDR4 و یک GPU GTX 1070 (راه اندازی 2016). بنابراین ، به سختی اوج سخت افزار نیست ، اما با توجه به اینکه این روزها چقدر بازی می کنم (و وقتی این کار را انجام می دهم ، بازی های ایندی قدیمی تر و کم مصرف را انتخاب می کنم) و GPU های مدرن مدرن چقدر گران هستند ، من از آنچه دارم خوشحالم.
با این حال ، همانطور که معلوم است ، شما به قدرتمندترین مدل هوش مصنوعی احتیاج ندارید. LLM های کمکی مدل های هوش مصنوعی هستند که با ساده کردن داده های مورد استفاده ، به طور خاص ، شماره های شناور ، کوچکتر و سریعتر ساخته شده اند.
به طور معمول ، هوش مصنوعی با شماره های با دقت بالا (مانند نقاط شناور 32 بیتی) عمل می کند ، که مقدار قابل توجهی از حافظه و پردازش را مصرف می کنند. کمیت این موارد را به شماره های با دقت پایین تر (مانند عدد صحیح 8 بیتی) کاهش می دهد بدون اینکه رفتار مدل را بیش از حد تغییر دهد. این بدان معناست که این مدل سریعتر اجرا می شود ، از ذخیره سازی کمتری استفاده می کند و می تواند روی دستگاه های کوچکتر (مانند تلفن های هوشمند یا سخت افزار لبه) کار کند ، هر چند که گاهی اوقات با کمی کاهش در دقت.
این بدان معنی است که اگرچه سخت افزار قدیمی من کاملاً برای اجرای یک LLM قدرتمند مانند مدل 205 میلیارد پارامتر Llama 3.1 تلاش می کند ، اما می تواند به جای آن 8B کوچکتر و کمیت را اجرا کند.
و هنگامی که OpenAI اولین مدل های استدلال کاملاً کم و با وزن خود را اعلام کرد ، فکر کردم وقت آن رسیده است که ببینم آنها روی سخت افزار قدیمی من چقدر خوب کار می کنند.
چگونه من از LLM محلی با استودیوی NVIDIA GTX 1070 و LM استفاده می کنم
این بخش را با گفتن اینکه من متخصص LLM های محلی نیستم و نه نرم افزاری که برای تهیه این مدل AI در دستگاه خود استفاده کرده ام ، به این بخش احتیاط می کنم. این دقیقاً همان کاری است که من برای بدست آوردن یک چت بابات هوش مصنوعی در GTX 1070 خود انجام دادم – و چقدر خوب کار می کند.
دانلود استودیوی LM
برای اجرای LLM محلی ، به برخی از نرم افزارها نیاز دارید. به طور خاص ، LM Studio ، ابزاری رایگان که به شما امکان می دهد LLM های محلی را روی دستگاه خود بارگیری و اجرا کنید. به صفحه اصلی LM Studio بروید و بارگیری را برای [سیستم عامل] انتخاب کنید (من از ویندوز 10 استفاده می کنم).
این یک فرآیند نصب استاندارد ویندوز است. تنظیمات را اجرا کرده و فرآیند نصب را تکمیل کرده و سپس LM Studio را راه اندازی کنید. من توصیه می کنم گزینه کاربر را انتخاب کنید زیرا برخی از گزینه های مفید را که ممکن است بخواهید از آن استفاده کنید ، نشان می دهد.
اولین مدل AI محلی خود را بارگیری کنید
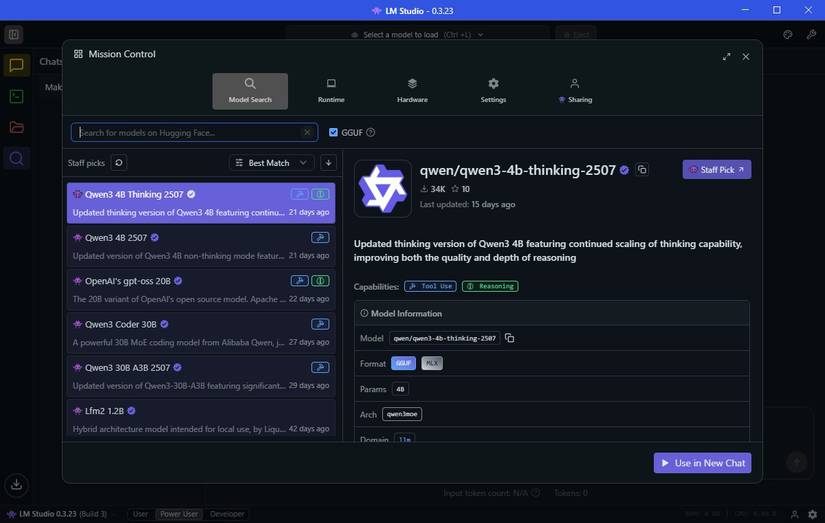
پس از نصب ، می توانید اولین LLM خود را بارگیری کنید. برگه Discover (نماد شیشه ذره بین) را انتخاب کنید. به راحتی ، LM Studio مدل های AI محلی را نشان می دهد که بهترین کار را روی سخت افزار شما انجام می دهند.
در مورد من ، این نشان می دهد که من مدلی به نام Qwen 3-4b-Tinking-25507 را بارگیری می کنم. نام مدل QWEN است (که توسط غول فناوری چینی Alibaba ساخته شده است) و سومین تکرار این مدل است. مقدار “4b” به این معنی است که این مدل دارای چهار میلیارد پارامتر برای پاسخ به شما است ، در حالی که “فکر کردن” به این معنی است که این مدل قبل از پاسخ دادن ، وقت خود را صرف نظر خود می کند. سرانجام ، 2507 آخرین باری است که این مدل به روز شد ، در 25 ژوئیه.
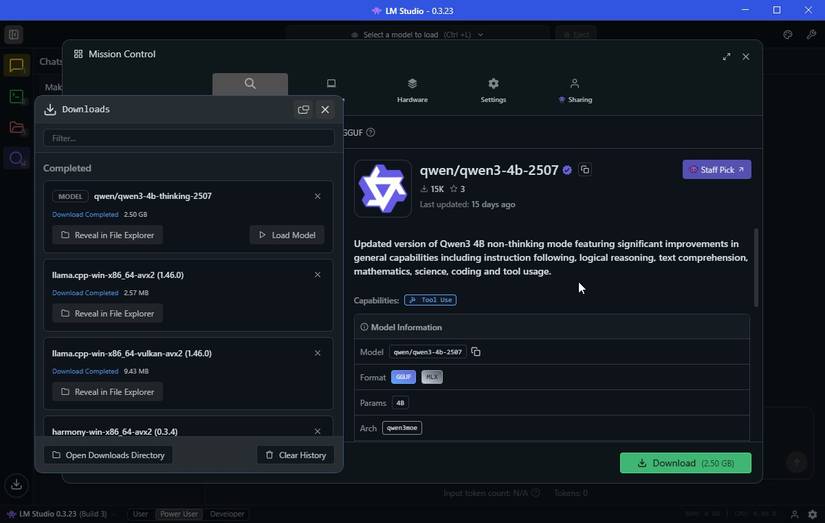
فکر کردن QWEN3-4B فقط 2.5 گیگابایت است ، بنابراین بارگیری طول نمی کشد. من قبلاً OpenAI/GPT-OSS-20B را نیز بارگیری کرده ام که در 12.11 گیگابایت بزرگتر است. همچنین دارای 20 میلیارد پارامتر است ، بنابراین باید پاسخ های “بهتر” را تحویل دهد ، اگرچه با هزینه منابع بالاتری همراه خواهد بود.
اکنون ، پیچیدگی های نام مدل AI را کنار بگذارید ، پس از بارگیری LLM ، تقریباً آماده استفاده از آن هستید.
قبل از بوت شدن مدل AI ، به برگه سخت افزار تغییر دهید و مطمئن شوید که LM Studio به درستی سیستم شما را مشخص می کند. همچنین می توانید به پایین بروید و نگهبان ها را در اینجا تنظیم کنید. من نگهبان را روی دستگاه خود قرار داده ام تا از مصرف بیش از حد از منابع بیش از حد استفاده کند ، و این می تواند باعث اضافه بار سیستم شود.
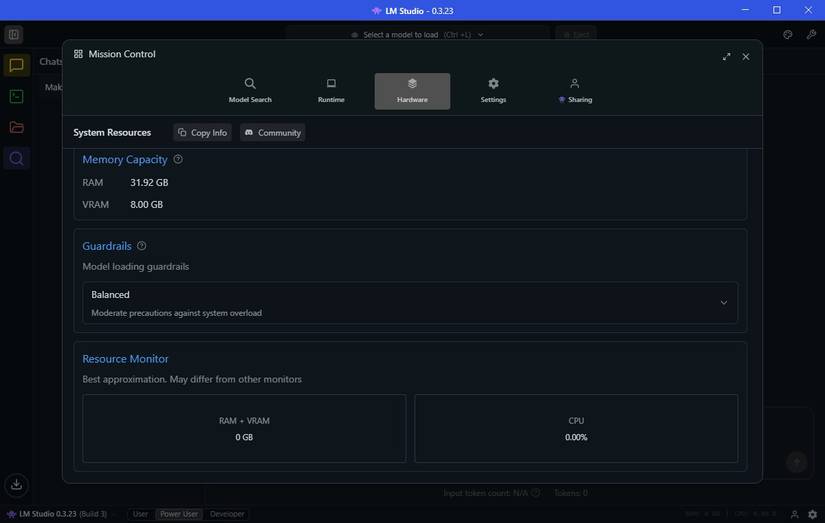
تحت GuardRails ، مانیتور منابع را نیز مشاهده خواهید کرد. این یک روش مفید برای دیدن چقدر از سیستم شما مدل AI است. اگر از سخت افزار کمی محدود مانند من استفاده می کنید ، باید توجه داشته باشید ، زیرا نمی خواهید سیستم شما به طور غیر منتظره خراب شود.
مدل AI خود را بارگیری کنید و شروع به فوریت کنید
اکنون شما آماده استفاده از یک چت بابات AI محلی در دستگاه خود هستید. در LM Studio ، نوار بالا را انتخاب کنید که به عنوان یک ابزار جستجو عمل می کند. با انتخاب نام AI ، مدل AI را در حافظه خود بارگذاری می کند و می توانید شروع به کار کنید.
اجرای یک مدل AI محلی بر روی سخت افزار قدیمی عالی است – اما بدون محدودیت
در اصل ، شما می توانید از مدل مانند آنچه که معمولاً می خواهید استفاده کنید ، اما محدودیت هایی وجود دارد. این مدل ها به همان اندازه قدرتمند نیستند که مثلاً GPT-5 در ChatGPT اجرا شود. علاوه بر این ، تفکر و پاسخ نیز بیشتر طول خواهد کشید و پاسخ ها ممکن است متفاوت باشد.
من یک تست کلاسیک LLM را در هر دو QWEN و GPT-OSS امتحان کردم ، و هر دو موفق شدم-در واقع.
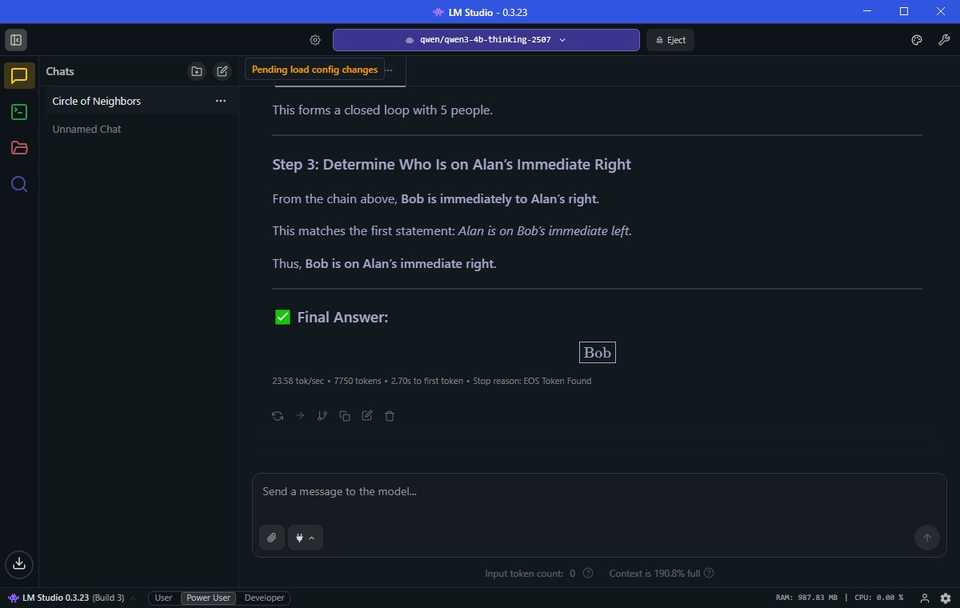
آلن ، باب ، کالین ، دیو و امیلی در یک دایره ایستاده اند. آلن در سمت چپ باب است. باب در سمت چپ کالین است. کالین در سمت چپ دیو است. دیو در سمت چپ فوری امیلی است. چه کسی در حق فوری آلن است؟
Qwen 5m11s را برای رسیدن به نتیجه گیری صحیح گرفت. GPT-5 فقط 45s طول کشید. اما توپ را از پارک بیرون می کشید؟ GPT-OSS-20B با 31 سریع.
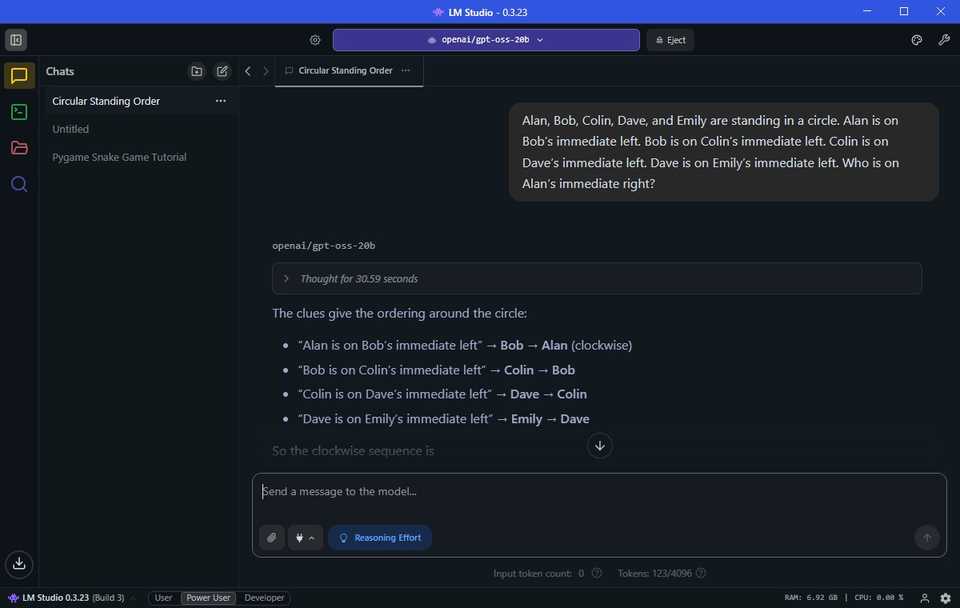

با این حال ، یک تست کافی نیست ، بنابراین من آن را در یک فوریه سریع AI امتحان کردم که برای آزمایش مهارت های استدلال هوش مصنوعی طراحی شده است. در یک آزمایش قبلی ، آخرین مدل OpenAi ، GPT-5 ، این کار را شکست داد ، بنابراین من مشتاق بودم که ببینم نسخه های آفلاین من از QWEN و GPT-OSS چگونه به آن رسیدگی می کنند.
شما در حال بازی رولت روسی با یک گرداننده شش تیرانداز هستید. حریف شما پنج گلوله را بارگیری می کند ، سیلندر را می چرخاند و به خودش آتش می زند. کلیک کنید – خالی. او این انتخاب را به شما ارائه می دهد: قبل از شلیک به سمت شما ، دوباره بچرخید ، یا این کار را نکنید. چه چیزی را انتخاب می کنید؟
Qwen در واقع پاسخ صحیح را در 1M41S ، که در واقع بسیار مناسب و معقول است (باز هم ، حسابداری برای محدودیت های سخت افزاری) را ترک کرد. اما باز هم ، GPT-5 در واقع این کار را شکست داد ، که من از آن کاملاً تعجب کردم. حتی این پیشنهاد را برای من ایجاد کرد که نشان می دهد چرا درست است. و دوباره ، GPT-OSS-20B پاسخ را در 9 ثانیه صحیح دریافت کرد.
در مناطق دیگر ، من نیز موفقیت فوری دیدم. من از GPT-OSS پرسیدم “آیا می توانید یک بازی مار را با استفاده از Pygame بنویسید” ، و با یک یا دو دقیقه ، من یک بازی کاملاً کارآمد از مار و در حال اجرا داشتم.
سخت افزار قدیمی شما می تواند یک مدل AI را اجرا کند
اجرای LLM محلی روی سخت افزار قدیمی به انتخاب مدل AI مناسب برای دستگاه شما می رسد. در حالی که نسخه Qwen کاملاً خوب کار کرده و بهترین پیشنهاد در استودیوی LM بود ، مشخص است که GPT-OSS-20B OpenAi گزینه بسیار بهتری است.
اما مهم است که انتظارات خود را متعادل کنید. اگرچه GPT-OSS با دقت به سؤالات پاسخ داد (و سریعتر از GPT-5) ، من نمی توانم مقدار زیادی از داده ها را برای پردازش در آن پرتاب کنم. محدودیت های سخت افزار من به سرعت نشان می دهد.
قبل از امتحان کردن ، من متقاعد شدم که اجرای یک چت بابات AI محلی بر روی سخت افزار قدیمی من غیرممکن است. اما به لطف مدل ها و ابزارهای کمکی مانند LM Studio ، نه تنها ممکن است – به طرز شگفت آور مفید است.
به گفته این ، شما همان سرعت ، لهستانی یا عمق استدلال را به عنوان چیزی مانند GPT-5 در ابر دریافت نخواهید کرد. اجرای محلی شامل معاملات است: شما حریم خصوصی ، دسترسی آفلاین و کنترل داده های خود را به دست می آورید ، اما از عملکرد خودداری می کنید.
با این وجود ، این واقعیت که یک GPU هفت ساله و یک CPU چهار ساله به هیچ وجه می توانند AI مدرن را اداره کنند بسیار هیجان انگیز است. اگر عقب نگه داشته شده اید زیرا به دلیل داشتن سخت افزار برش ، مدل های محلی با سرعت ممکن نیست راه شما به دنیای AI آفلاین باشد.