
با داده های خود در DataFrame، با حسن نیت از کتابخانه پانداها، مرتب کردن آنها با استفاده از این رویکردهای مختلف آسان است.
دارایی های داده های بزرگ آشفته هستند، به خصوص زمانی که باید آنها را از وب سایت ها، سرورها یا سایر منابع داده بیرون بکشید.
برنامه های کاربردی مبتنی بر UI مانند MS Excel برای برخورد با مجموعه داده های ساده خوب هستند، اما زمانی که داده ها بزرگتر می شوند، ممکن است مشکل داشته باشند. این دلیل خوبی است برای اینکه شما به پایتون بروید تا عملیات پیچیده تری مبتنی بر داده را انجام دهید.
کتابخانه شخص ثالث پایتون، پانداها، به شما کمک می کند مجموعه داده های موجود خود را سریع مرتب کنید. اگر به دنبال مرتبسازی دادههای خود در پایتون هستید، این مقاله به چند روش برای دستیابی به این کار میپردازد.
پیش نیازهای استفاده از پایتون برای مرتب سازی داده ها
قبل از مرتب سازی داده های خود در پایتون، باید چند پیش نیاز را رعایت کنید:
- یک IDE پایتون را دانلود کنید. میتوانید از یک IDE سازگار با پایتون، مانند Jupyter Notebook، PyCharm، و Spyder و غیره استفاده کنید. هر کدام از این ها با تمام نسخه های پایتون سازگار است.
- پانداها را نصب کنید شما به بسته پاندا نیاز دارید که می توانید با استفاده از PIP یا روش دلخواه خود آن را نصب کنید.
- مجموعه داده نمونه یک مجموعه داده نمونه را برای تمرین کدهای فهرست شده دانلود کنید. از طرف دیگر، می توانید از این رویه ها در داده های انحصاری خود استفاده کنید.
وارد کردن کتابخانه پانداها در پایتون
Pandas یک کتابخانه پایتون شخص ثالث است که می توانید از آن برای مدیریت اکسل، CSV و سایر فرمت های داده استفاده کنید.
برای کار با یک نمونه فایل اکسل، با وارد کردن کتابخانه pandas شروع کنید. پس از آن، از رویه import برای خواندن داده های اکسل در پایتون استفاده خواهید کرد.
برای وارد کردن کتابخانه
import pandas as pd
یک DataFrame جدید برای بارگیری داده های اکسل ایجاد کنید
file = "Sample - Superstore.xls"
df = pd.read_excel(file)
df.head()
جایی که:
- df یک شی DataFrame است که داده های وارد شده را ذخیره می کند.
- pd نام مستعار کتابخانه پانداها است.
- read_excel روشی برای خواندن فایل اکسل در پایتون است.
- فایل مسیری به فایل اکسل است.
- head متدی است که پنج سطر اول را از DataFrame برمی گرداند.
هنگامی که برنامه شما داده ها را بارگذاری کرد، می توانید از بسیاری از روش های موجود DataFrame برای مرتب سازی آن ها به روش های مختلف استفاده کنید.
1. مرتب سازی بر اساس یک ستون در یک DataFrame
از آنجایی که دادههای شما دارای ردیفها و ستونهای زیادی هستند، اغلب میخواهید دادهها را بر اساس یک ستون یا ستون خاص مرتب کنید.
پایتون به صورت پیش فرض داده ها را به ترتیب صعودی مرتب می کند. اگر می خواهید ترتیب مرتب سازی را تغییر دهید، باید به صراحت آن را در کد خود ذکر کنید.
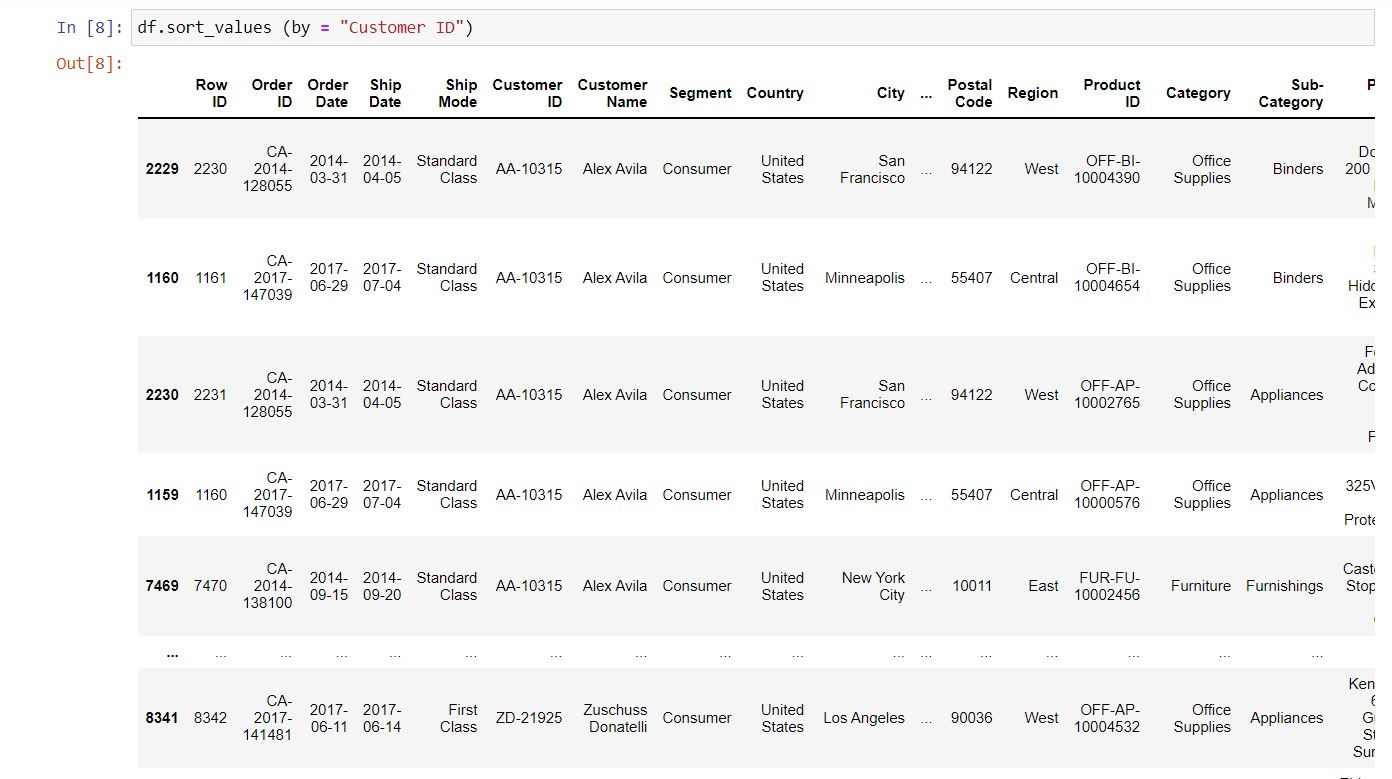
مرتب سازی بر اساس یک ستون (به ترتیب صعودی)
df.sort_values(by = "Customer ID")
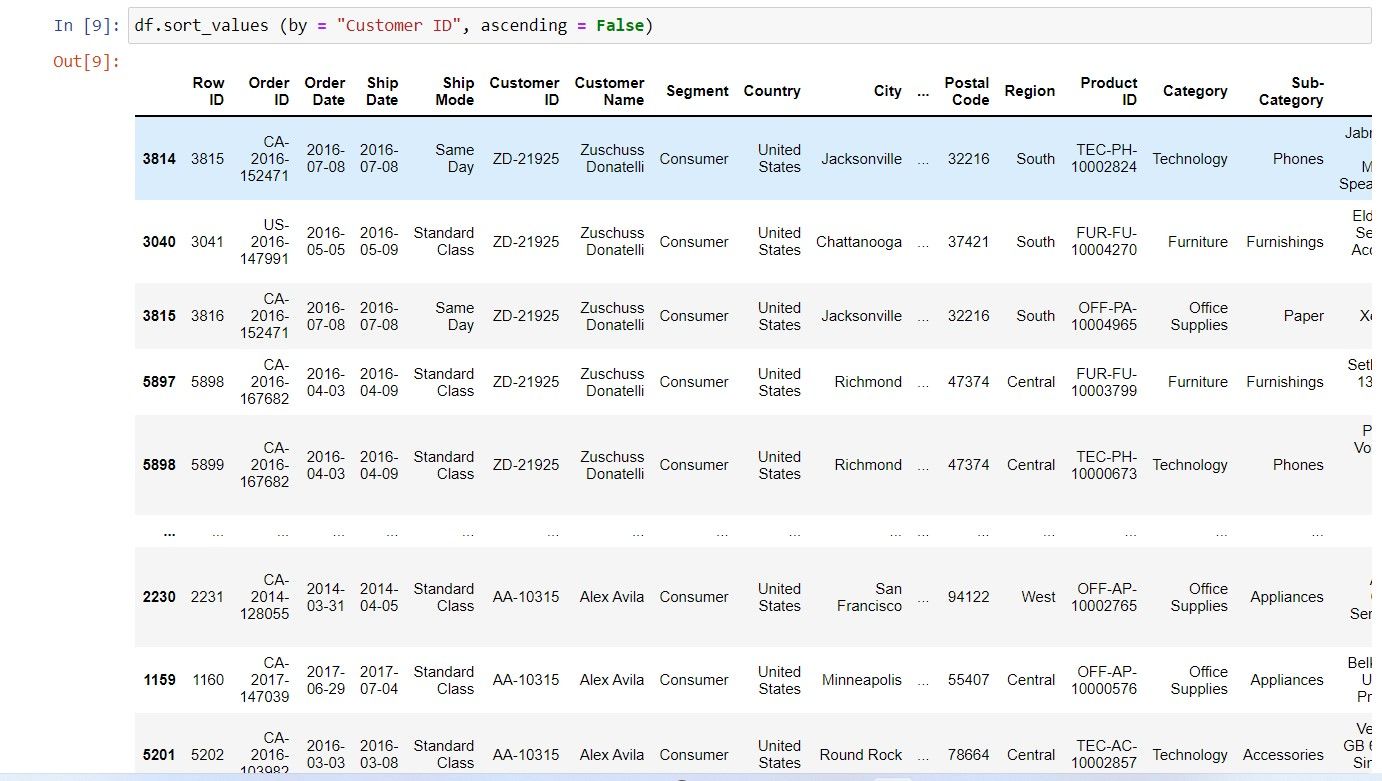
مرتب سازی بر اساس یک ستون (نزولی)
پارامتر صعودی را روی False قرار دهید تا ستون شما به ترتیب نزولی مرتب شود.
df.sort_values(by = "Customer ID", ascending=False)
جایی که:
- df یک شی DataFrame است که حاوی داده ها است.
- sort_values روشی برای مرتب سازی بر اساس مقادیر داده است.
- by پارامتری برای تعریف نام ستون است.
- صعودی پارامتری برای تعریف ترتیب مرتب سازی است.
2. مرتب سازی ستون های متعدد در یک DataFrame
اگر نیاز شما به آن نیاز دارد، همچنین می توانید DataFrame(های) خود را بر اساس چندین ستون به طور همزمان مرتب کنید. در چنین سناریویی، شما باید ارجاعات ستون را در یک لیست تعریف کنید.
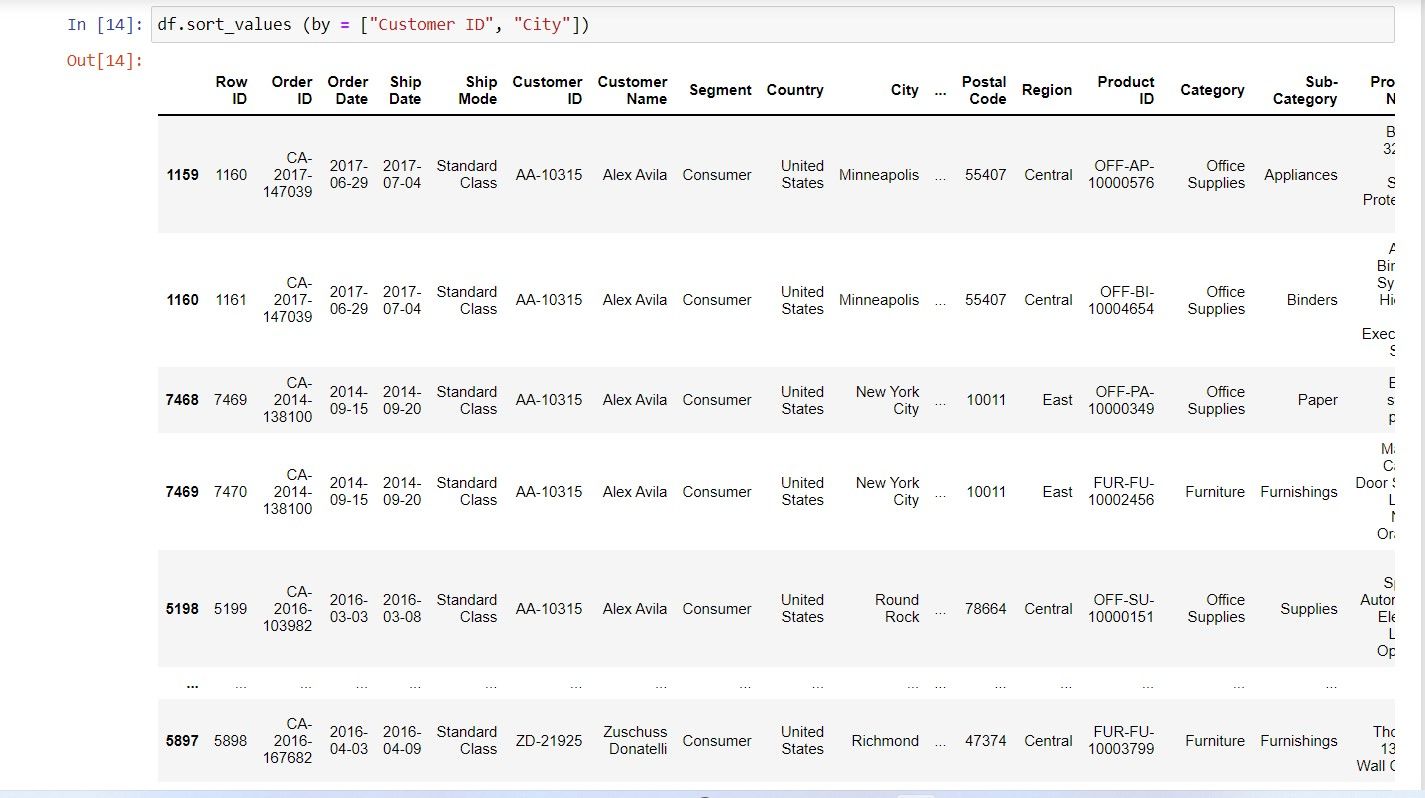
مرتب سازی بر اساس چند ستون صعودی
df.sort_values(by = ["Customer ID", "City"])
مرتب سازی بر اساس چند ستون نزولی
از تابع ascending = False برای مرتب سازی ستون های خود به ترتیب نزولی استفاده کنید. به یاد داشته باشید، شما باید نام ستون ها را در یک لیست مشخص کنید تا آنها را به طور همزمان مرتب کنید.
df.sort_values(by = ["Customer ID", "City"], ascending = False)
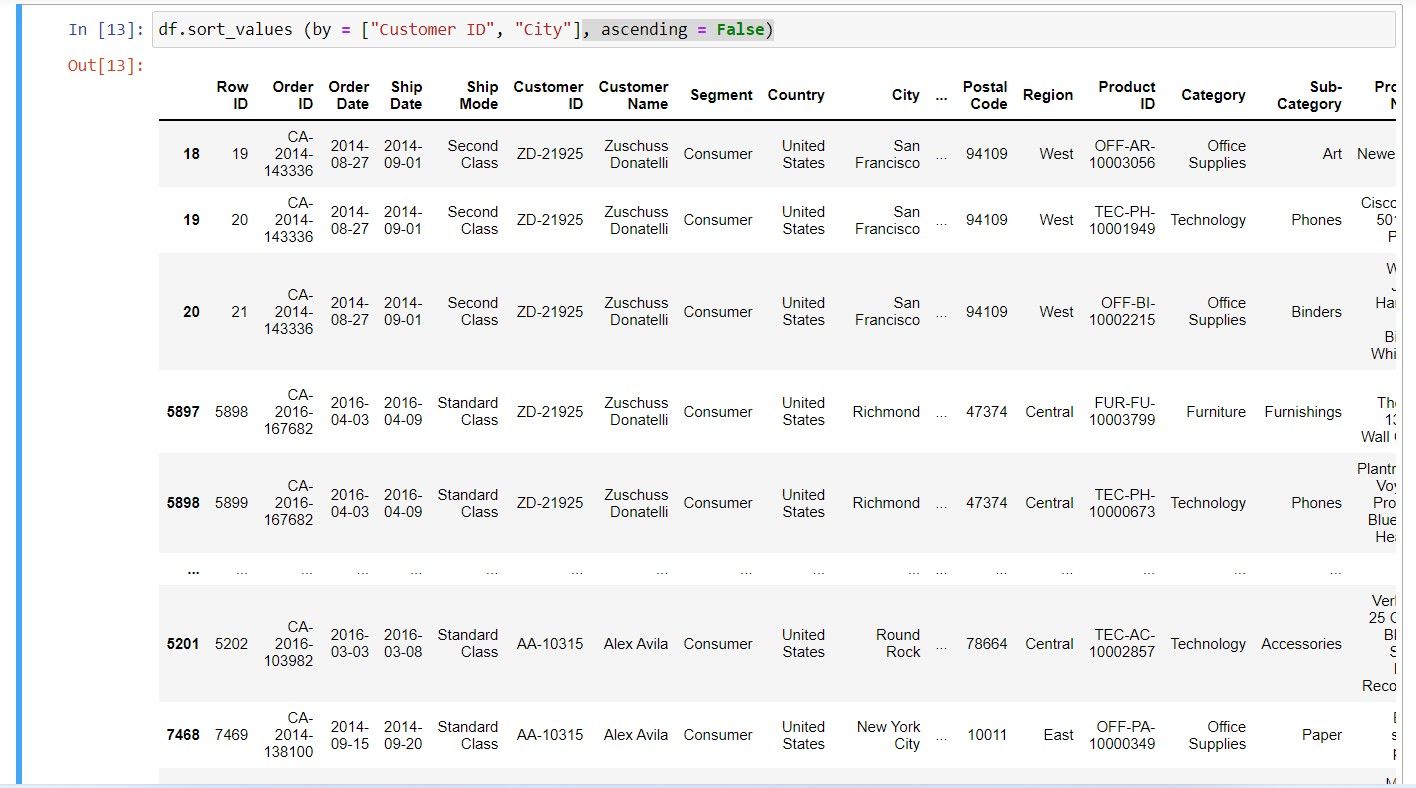
مرتب سازی بر اساس ستون های متعدد به ترتیب های مختلف
با اصول مرتب سازی خارج از مسیر، چه اتفاقی می افتد وقتی می خواهید یک ستون را به ترتیب نزولی و دیگری را به ترتیب صعودی مرتب کنید؟ شما باید کد خود را کمی تغییر دهید تا این الزامات را در خود جای دهد.
به عنوان مثال، برای مرتب سازی ستون های منطقه و شهر به ترتیب نزولی و صعودی:
df.sort_values(by = ["Region", "City"], ascending = [False, True])
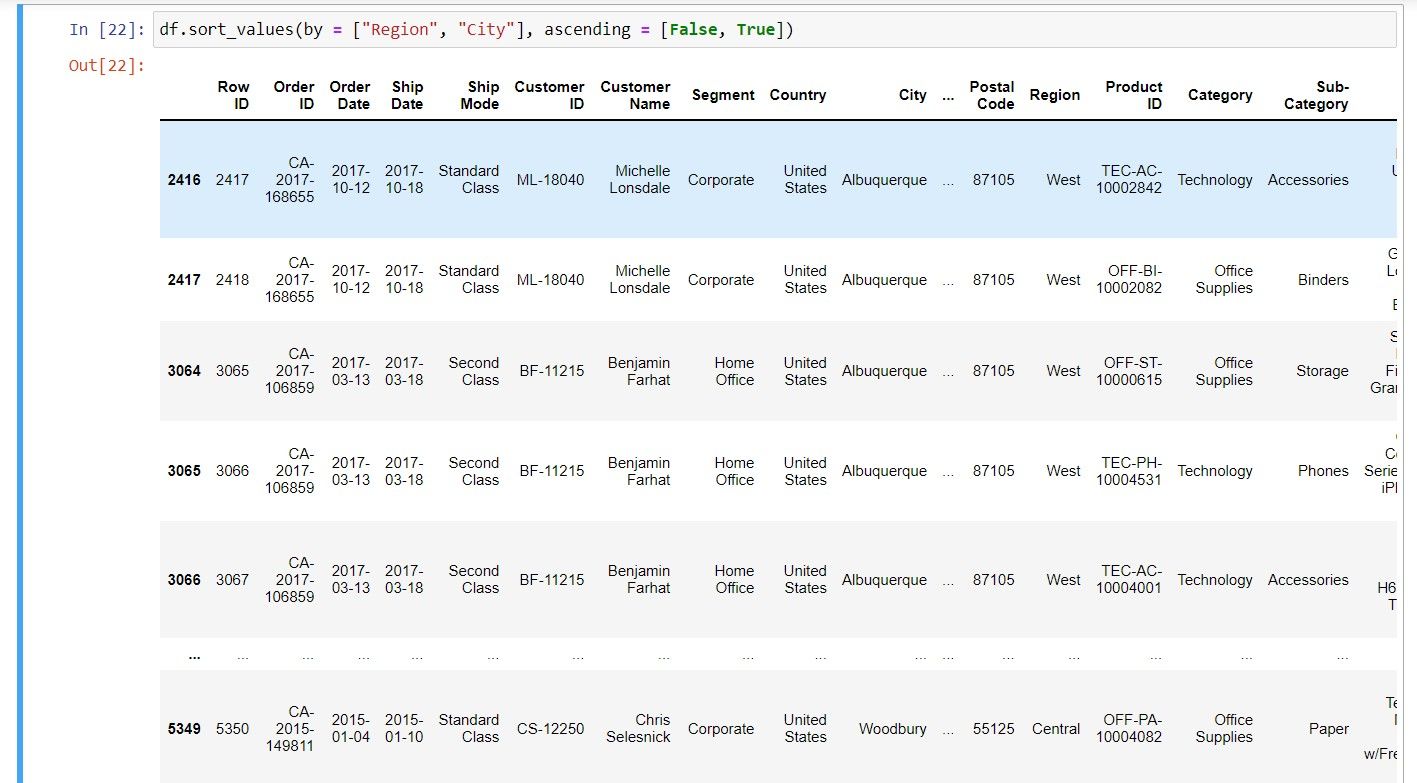
توضیح این کد ساده است. شما نام DataFrame را تعریف می کنید و تابع sort_values را به همراه نام ستون ها در یک لیست ارسال می کنید. برای تعیین ترتیب مرتب سازی باید از مقادیر بولی استفاده کنید.
فراخوانی تابع به این صورت به این معنی است که پایتون ابتدا بر اساس ستون DataFrame’s Region به ترتیب نزولی مرتب می شود. سپس، ردیفهایی با منطقه یکسان توسط ستون شهر به ترتیب صعودی مرتب میشوند.
3. نحوه مرتب سازی ستون ها در یک DataFrame بر اساس شاخص
متغیر ایندکس مقدار پیش فرضی است که به هر ردیف در یک Dataframe پایتون اختصاص داده می شود. می توانید مقادیر شاخص را تعریف کنید یا اجازه دهید پایتون یک مقدار شاخص را به تنهایی تعیین کند.
برای مرتب سازی داده ها بر اساس مقدار شاخص آن، می توانید از تابع sort_index استفاده کنید. این تابع بر اساس شاخص مرتب می شود نه بر اساس مقادیر موجود در مجموعه داده اصلی.
df.sort_index()
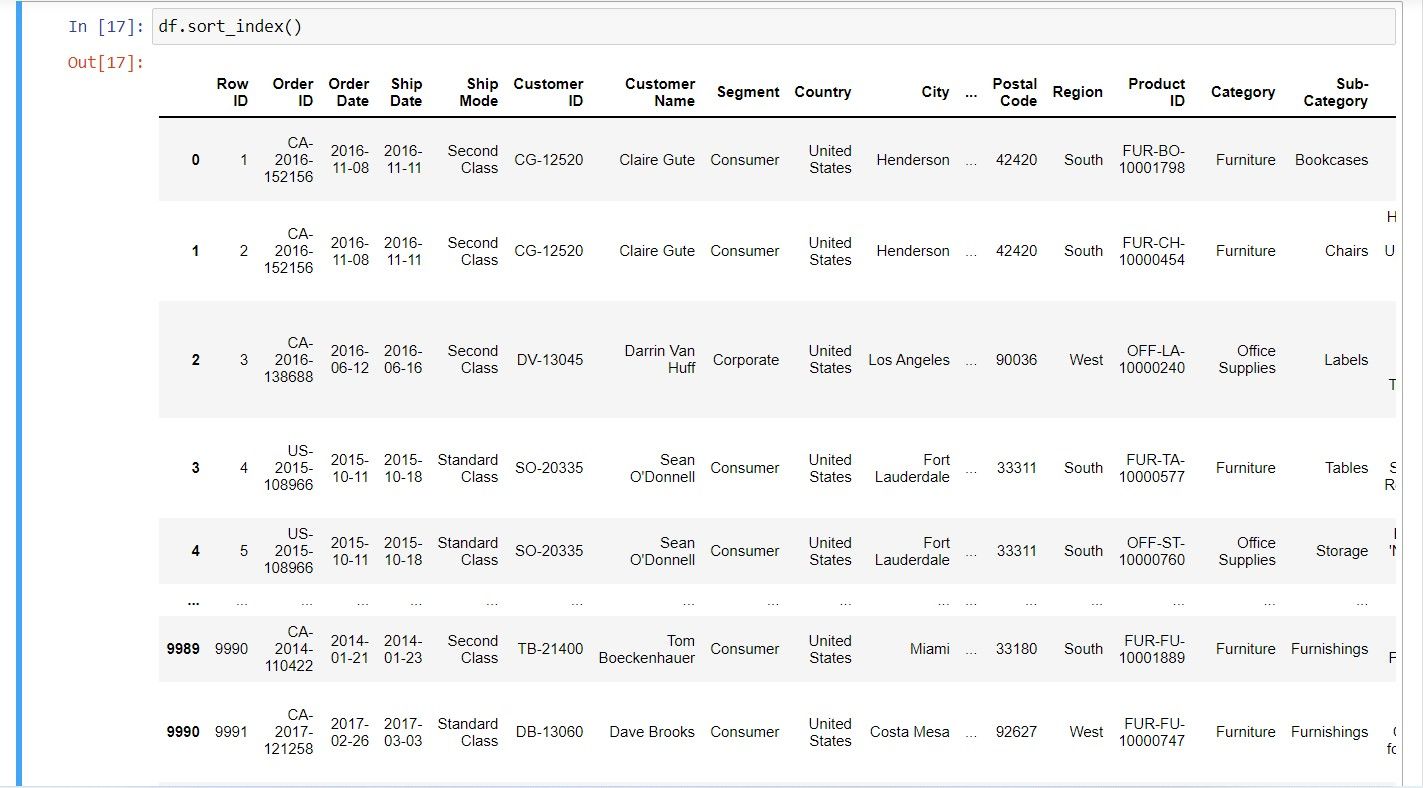
همانند sort_values، می توانید یک پارامتر صعودی را برای تعیین جهت مرتب سازی ارسال کنید. به عنوان مثال، مقدار False را برای مرتب کردن داده ها به ترتیب نزولی ارسال کنید:
df.sort_index(ascending = False)
-1.jpg)
4. مرتب سازی ستون ها در یک DataFrame به جای ردیف
به جای مرتب کردن ردیف ها در یک DataFrame، می توانید ستون های آن را مرتب کنید. می توانید این کار را با فراخوانی متد sort_index و ارسال پارامتر محوری با مقدار 1 انجام دهید:
df.sort_index(axis=1)
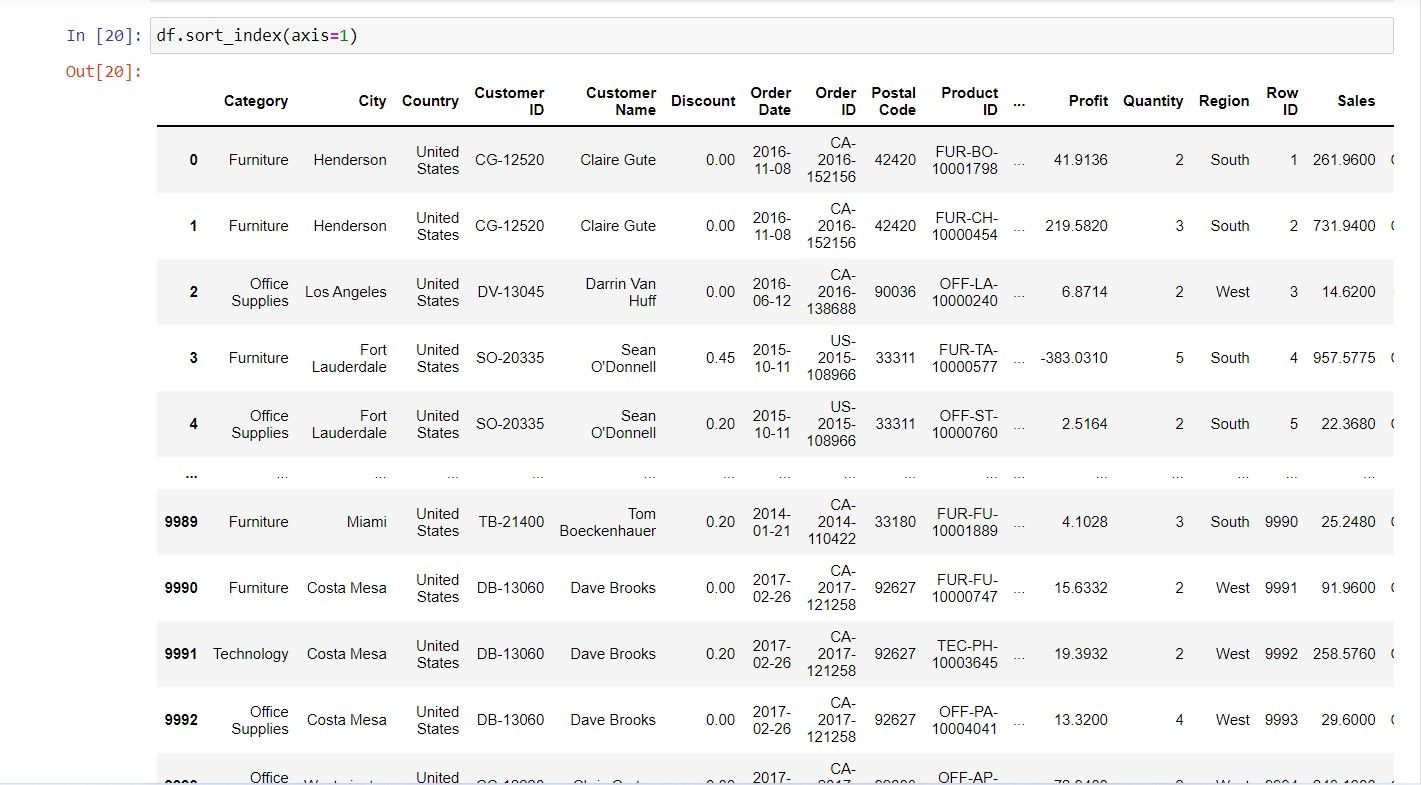
این مرحله DataFrame را بر اساس ستون های آن به ترتیب صعودی مرتب می کند. برای مرتبسازی ستونهای DataFrame به ترتیب نزولی، میتوانید ترتیب مرتبسازی را در مرحله مرتبسازی خود مشخص کنید.
df.sort_index(axis=1, ascending = False)
.jpg)
5. اصلاح DataFrame هنگام مرتب سازی آن
دو روش مرتبسازی با بازگرداندن یک کپی از دادههای اصلی، در حالت مرتبسازی شده جدید کار میکنند. برای صرفه جویی در فضای ذخیره سازی یا صرفاً برای نوشتن کد مختصرتر، می توانید داده های اصلی DataFrame را تغییر دهید. هر روش یک پارامتر بولی داخلی را می پذیرد که به جای بازگرداندن یک کپی اصلاح شده، داده ها را اصلاح می کند.
df.sort_values(by = ["Customer ID", "City"], ascending = False, inplace = True)
آموزش مرتب سازی داده ها در پایتون
پایتون بسیاری از توابع داخلی اکسل را با چند خط کد تکرار می کند. از روشهای مرتبسازی گرفته تا ایجاد جداول Pivot مفصل روی دادههای خود، نام آنها را میگذارید و میتوانید آن را در پایتون انجام دهید.
اگر هنوز با پایتون تازه کار هستید و طناب ها را یاد می گیرید، این مراحل مهارت های کدنویسی شما را نسبتاً آسان تر می کند.