
مجموعه داده ها را با استفاده از کتابخانه پانداها به روش های مختلف ترکیب کنید.
به عنوان یک تحلیلگر داده، اغلب با نیاز به ترکیب مجموعه داده های متعدد مواجه خواهید شد. شما باید این کار را انجام دهید تا تجزیه و تحلیل خود را کامل کنید و به یک نتیجه برای کسب و کار / سهامداران خود برسید.
وقتی دادهها در جداول مختلف ذخیره میشوند، اغلب چالشبرانگیز است. در چنین شرایطی، بدون در نظر گرفتن زبان برنامه نویسی که روی آن کار می کنید، join ها ارزش خود را ثابت می کنند.
پیوندهای پایتون مانند اتصالات SQL هستند: آنها مجموعه دادهها را با تطبیق ردیفهایشان در یک شاخص مشترک ترکیب میکنند.
دو DataFrame برای مرجع ایجاد کنید
برای دنبال کردن مثالهای این راهنما، میتوانید دو نمونه DataFrame ایجاد کنید. از کد زیر برای ایجاد اولین DataFrame استفاده کنید که شامل شناسه، نام و نام خانوادگی است.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)
برای اولین قدم، کتابخانه پانداها را وارد کنید. سپس می توانید از یک متغیر a برای ذخیره نتیجه از سازنده DataFrame استفاده کنید. یک فرهنگ لغت حاوی مقادیر مورد نیاز خود را به سازنده منتقل کنید.
در نهایت، محتویات مقدار DataFrame را با تابع چاپ نمایش دهید تا بررسی کنید همه چیز همانطور که انتظار دارید به نظر می رسد.
به طور مشابه، می توانید DataFrame دیگری، b ایجاد کنید که حاوی ID و مقادیر حقوق و دستمزد است.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)
می توانید خروجی را در یک کنسول یا یک IDE بررسی کنید. باید محتویات DataFrames شما را تأیید کند:
Join ها چه تفاوتی با تابع Merge در پایتون دارند؟
کتابخانه پانداها یکی از کتابخانه های اصلی است که می توانید از آن برای دستکاری DataFrames استفاده کنید. از آنجایی که DataFrames حاوی چندین مجموعه داده است، توابع مختلفی در پایتون برای پیوستن به آنها موجود است.
پایتون توابع join و ادغام را در میان بسیاری دیگر ارائه می دهد که می توانید از آنها برای ترکیب DataFrames استفاده کنید. تفاوت فاحشی بین این دو عملکرد وجود دارد که قبل از استفاده از هر کدام باید آن را در نظر داشته باشید.
تابع join دو DataFrame را بر اساس مقادیر شاخص آنها به هم می پیوندد. تابع ادغام DataFrames را بر اساس مقادیر شاخص و ستون ها ترکیب می کند.
چه چیزی باید در مورد Join در پایتون بدانید؟
قبل از بحث در مورد انواع اتصالات موجود، در اینجا به چند نکته مهم توجه کنید:
- اتصالات SQL یکی از اساسی ترین توابع هستند و کاملاً شبیه اتصالات پایتون هستند.
- برای پیوستن به DataFrames می توانید از متد ()pandas.DataFrame.join استفاده کنید.
- اتصال پیشفرض یک اتصال چپ را انجام میدهد، در حالی که تابع ادغام یک اتصال داخلی را انجام میدهد.
نحو پیش فرض برای پیوستن پایتون به شرح زیر است:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)
متد join را در DataFrame اول فراخوانی کنید و DataFrame دوم را به عنوان اولین پارامتر آن ارسال کنید. استدلال های باقی مانده عبارتند از:
- در، که در صورت وجود بیش از یک فهرست، فهرستی را برای پیوستن به آن نام میبرد.
- how، که نوع اتصال شامل داخلی، خارجی، چپ و راست را تعریف می کند.
- lsuffix، که رشته پسوند سمت چپ نام ستون شما را تعریف می کند.
- rssuffix، که رشته پسوند سمت راست نام ستون شما را تعریف می کند.
- مرتب سازی، که یک بولی است که نشان می دهد آیا DataFrame حاصل باید مرتب شود یا خیر.
آموزش استفاده از انواع اتصالات در پایتون
پایتون چند گزینه پیوستن دارد که بسته به نیاز ساعت می توانید آنها را تمرین کنید. در اینجا انواع اتصال آورده شده است:
1. عضویت را ترک کنید
اتصال سمت چپ مقادیر DataFrame اول را دست نخورده نگه میدارد در حالی که مقادیر منطبق را از دومی وارد میکند. به عنوان مثال، اگر می خواهید مقادیر مطابق با b را وارد کنید، می توانید آن را به صورت زیر تعریف کنید:
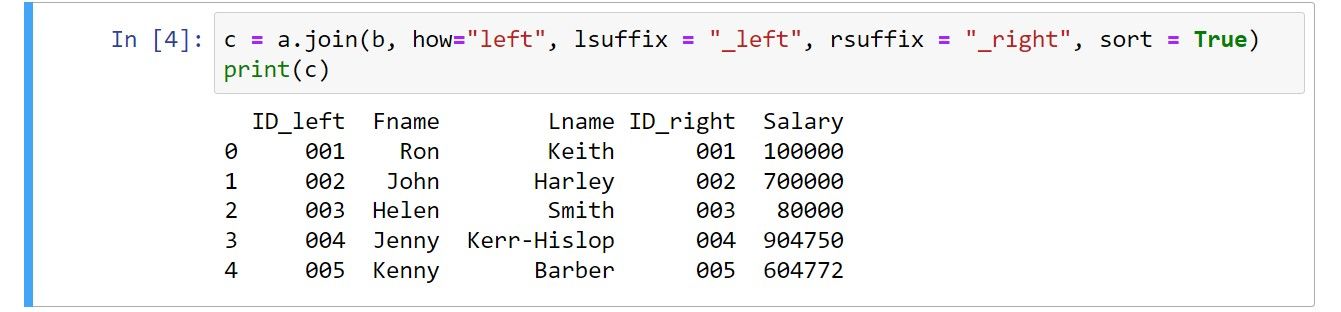
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)
هنگامی که پرس و جو اجرا می شود، خروجی حاوی ارجاعات ستون زیر است:
- ID_سمت چپ
- Fname
- Lname
- ID_right
- حقوق
این اتصال، سه ستون اول را از DataFrame اول و دو ستون آخر را از DataFrame دوم می کشد. از مقادیر lsuffix و rssuffix برای تغییر نام ستونهای ID از هر دو مجموعه داده استفاده کرده است و اطمینان حاصل میکند که نام فیلدهای حاصل منحصربهفرد هستند.
خروجی به صورت زیر است:
2. سمت راست Join
اتصال سمت راست مقادیر DataFrame دوم را دست نخورده نگه می دارد، در حالی که مقادیر منطبق را از جدول اول وارد می کند. به عنوان مثال، اگر می خواهید مقادیر منطبق را از a بیاورید، می توانید آن را به صورت زیر تعریف کنید:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)
خروجی به صورت زیر است:
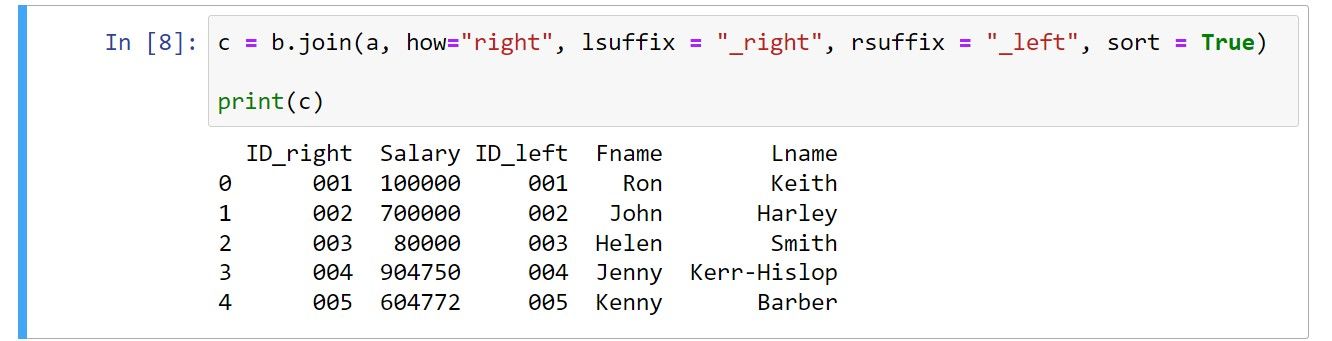
اگر کد را مرور کنید، چند تغییر آشکار وجود دارد. برای مثال، نتیجه شامل ستونهای DataFrame دوم قبل از ستونهای DataFrame اول است.
شما باید از مقدار right برای آرگومان how استفاده کنید تا یک اتصال راست را مشخص کنید. همچنین، توجه داشته باشید که چگونه می توانید مقادیر lsuffix و rssuffix را تغییر دهید تا ماهیت اتصال سمت راست را منعکس کنید.
در اتصالات معمولی خود، ممکن است در مقایسه با اتصال راست، بیشتر از اتصالات چپ، داخلی و خارجی استفاده کنید. با این حال، استفاده کاملاً به نیازهای داده شما بستگی دارد.
3. پیوستن داخلی
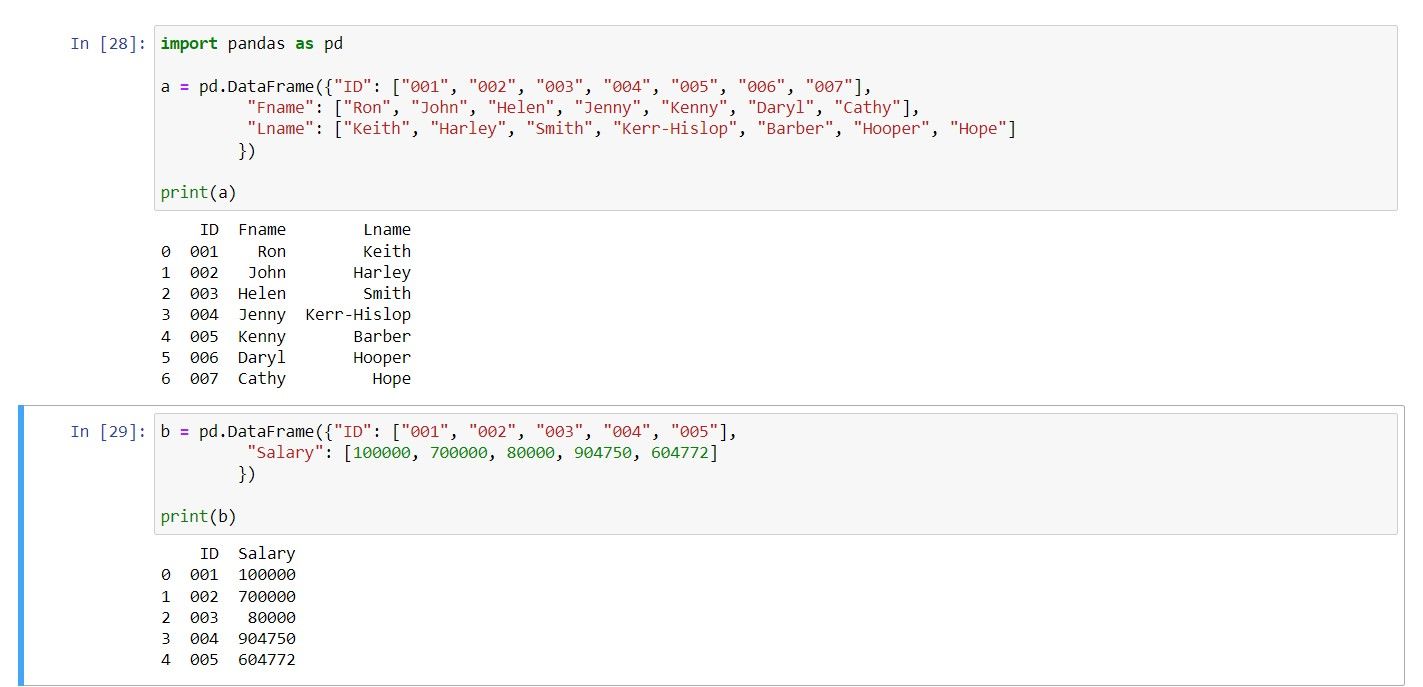
یک اتصال داخلی ورودی های تطبیق را از هر دو DataFrame تحویل می دهد. از آنجایی که اتصال ها از اعداد شاخص برای مطابقت با ردیف ها استفاده می کنند، اتصال داخلی فقط ردیف هایی را که مطابقت دارند برمی گرداند. برای این تصویر، از دو DataFrame زیر استفاده می کنیم:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)
خروجی به صورت زیر است:
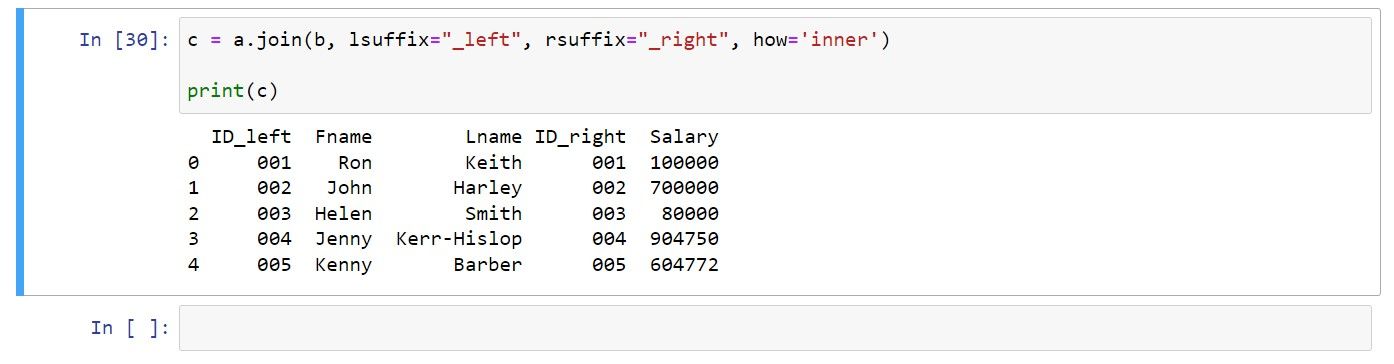
می توانید از اتصال داخلی به شرح زیر استفاده کنید:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)
خروجی حاصل فقط شامل ردیف هایی است که در هر دو DataFrame ورودی وجود دارند:
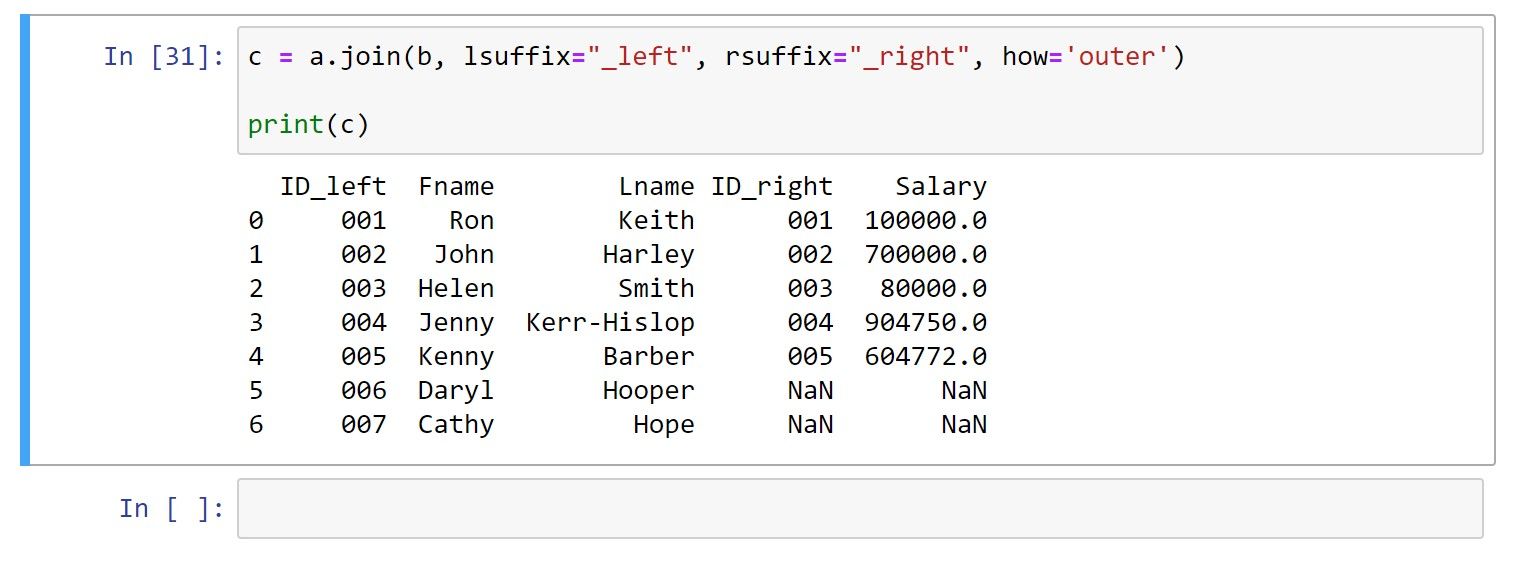
4. پیوستن خارجی
یک اتصال بیرونی تمام مقادیر هر دو DataFrame را برمی گرداند. برای ردیفهایی که مقادیر تطبیقی ندارند، یک مقدار تهی در سلولهای جداگانه ایجاد میکند.
با استفاده از همان DataFrame فوق، در اینجا کد برای اتصال خارجی آمده است:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)
استفاده از Joins در پایتون
اتصالات، مانند توابع همتای خود، ادغام و ادغام، چیزی بیش از یک قابلیت اتصال ساده ارائه می دهند. با توجه به مجموعه ای از گزینه ها و عملکردهای آن، می توانید گزینه هایی را انتخاب کنید که نیازهای شما را برآورده می کند.
شما می توانید مجموعه داده های حاصل را نسبتاً آسان، با یا بدون تابع join، با گزینه های انعطاف پذیری که پایتون ارائه می دهد، مرتب کنید.