پایگاه های داده برداری در جامعه هوش مصنوعی تجدید حیات یافته اند و این نحوه کار آنهاست.
پایگاه های داده برداری به دلیل در دسترس بودن گسترده مدل های هوش مصنوعی از پیش آموزش دیده، احیا شده اند. اگرچه مفهوم پایگاه داده برداری چندین دهه است که وجود داشته است، اما اکنون، در عصر مدل های زبان بزرگ (LLM) است که می توان از پایگاه داده های برداری با پتانسیل کامل خود استفاده کرد.
پایگاه داده های برداری به ویژه در برنامه هایی مانند سیستم های توصیه، جستجوی شباهت تصویر، تشخیص ناهنجاری، تشخیص چهره و برنامه های پردازش زبان طبیعی مفید هستند.
بنابراین، پایگاه داده برداری دقیقاً چیست؟ چگونه کار می کند و چه زمانی باید از آنها برای تقویت قابلیت های هوش مصنوعی استفاده کرد؟
پایگاه داده برداری چیست؟
پایگاه داده برداری راهی برای ذخیره اطلاعات از طریق استفاده از بردارها است. برخلاف شکل معمول پایگاه های داده که داده ها را به صورت فهرست های جدول بندی شده سازماندهی می کنند، پایگاه های داده برداری داده ها را از طریق بردارهای با ابعاد بالا سازماندهی می کنند. سپس این بردارها را می توان در فضای ریاضی به عنوان جاسازی های برداری نشان داد.
پایگاه داده های برداری مهم هستند زیرا این جاسازی های برداری را در خود نگه می دارند و ویژگی هایی مانند نمایه سازی، معیارهای فاصله و جستجوی شباهت بر اساس جاسازی های برداری را ارائه می دهند.
پایگاه داده های برداری سرویس هایی هستند که به راحتی می توانند با یک مدل از پیش آموزش دیده ادغام شوند، که بسیاری از آنها برای دسترسی به سرویس به یک کلید API نیاز دارند.
جاسازی های برداری چیست؟
به عبارت ساده، جاسازی های برداری یا به سادگی جاسازی ها، نمایش های عددی یک موضوع یا یک کلمه هستند. به عنوان مثال، یک جاسازی دو بعدی ممکن است شبیه “2، -3” باشد، که در آن 2 نشان دهنده دو واحد در جهت مثبت در امتداد محور x است، در حالی که -3 نشان دهنده سه واحد منفی در امتداد محور y است. در حالی که یک جاسازی سه بعدی شبیه “2، -3، 5” است، که در آن پنج نقطه داده را 5 واحد در جهت مثبت محور z قرار می دهد.
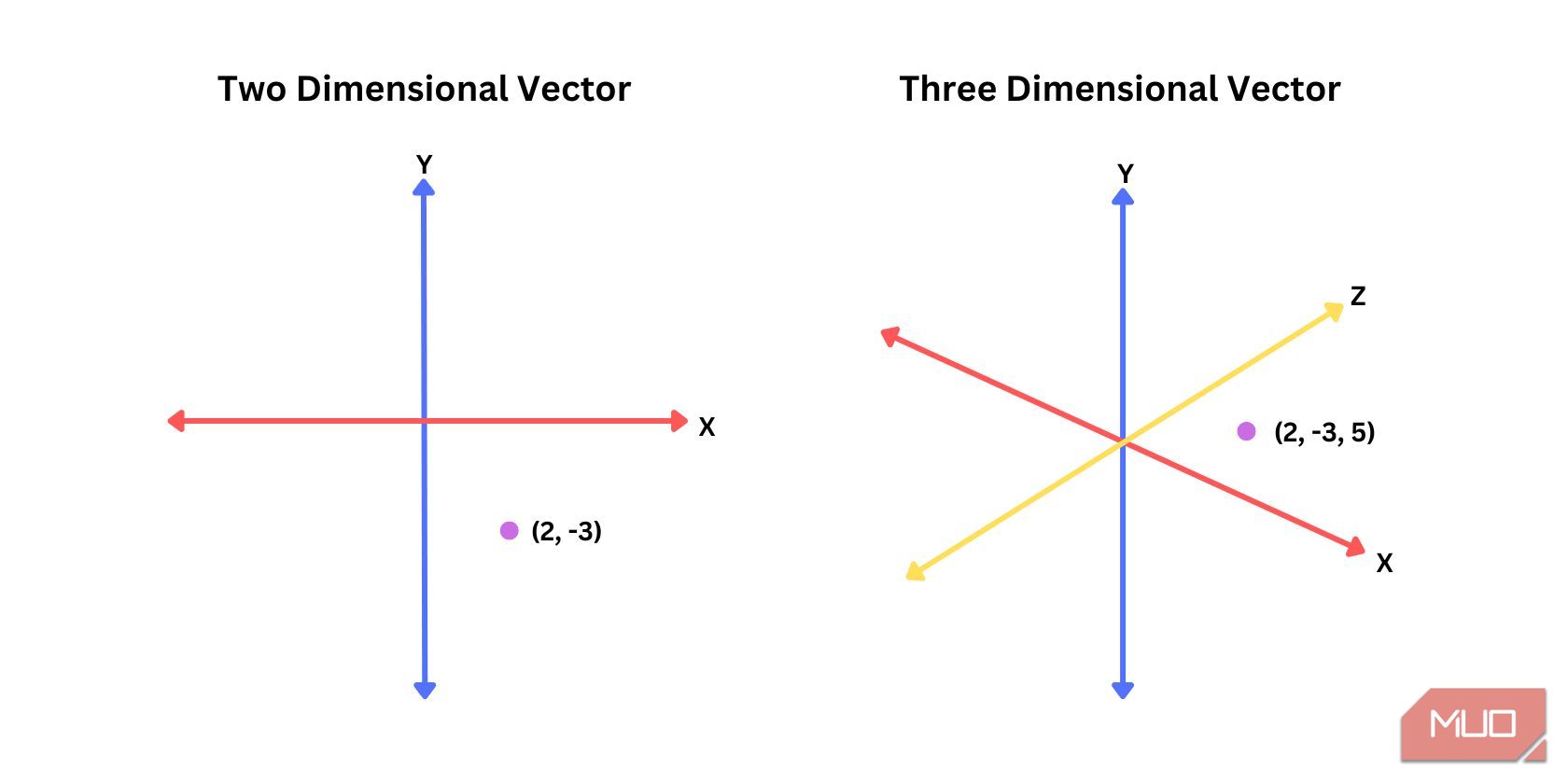
داشتن ابعاد بیشتر زمینه بیشتری را برای آنچه که یک قطعه داده باید باشد فراهم می کند. تعداد ابعاد مورد استفاده در پایگاه داده برداری اغلب از 100 تا 300 بعد برای NLP و چند صد بعد برای بینایی کامپیوتر متغیر است.
تولید جاسازی های برداری مستلزم استفاده از مدل ها و ابزارهای جاسازی برداری مانند BERT، CNN و RNN است.
چرا جاسازی های برداری مهم هستند؟
داشتن توانایی ترسیم مکان داده ها در فضای ریاضی به رایانه ها این امکان را می دهد که رابطه بین نقاط داده و میزان ارتباط قوی آنها با یکدیگر را درک کنند. با دانستن میزان همبستگی بین هر نقطه داده، یک مدل هوش مصنوعی توانایی درک پرس و جوها را به روشی متنی مانند یک انسان خواهد داشت.
بدون درک معناشناسی یا زمینه، یک هوش مصنوعی ممکن است پاسخهای منطقی درست اما از نظر متنی اشتباه ارائه دهد. به عنوان مثال، هوش مصنوعی ممکن است عبارت «او قلب سنگینی داشت در حالی که راه میرفت» را بهعنوان یک مرد مبتلا به ناراحتی قلبی به جای اینکه یک مرد احساس غمگینی یا سنگینی کند، اشتباه تفسیر کند.
چگونه پایگاه های داده برداری به تقویت هوش مصنوعی کمک می کنند
جاسازی های برداری مولفه های مهمی در آموزش انواع مدل های هوش مصنوعی هستند. داشتن یک پایگاه داده تخصصی که می تواند جاسازی های برداری را ذخیره، فهرست و پرس و جو کند، برای به حداکثر رساندن مزایای استفاده از جاسازی های برداری ضروری است. علاوه بر این، پایگاههای داده برداری، هوش مصنوعی شما را با یک پایگاه داده سریع، قابل اعتماد و مقیاسپذیر تقویت میکنند که میتواند به طور مداوم به رشد و آموزش یک مدل هوش مصنوعی کمک کند.
از آنجایی که پایگاههای داده برداری میتوانند قابلیتهای یک مدل هوش مصنوعی را گسترش دهند، کسبوکارها و سازمانها ممکن است از یک پایگاه داده برداری برای برنامههای مختلف استفاده کنند، از جمله:
- موتورهای جستجو: گاهی اوقات، افراد نمی دانند از چه کلمات کلیدی هنگام پرس و جو استفاده کنند. یک پایگاه داده برداری به سیستم کمک می کند تا با تجزیه و تحلیل زمینه و بازیابی نزدیک ترین کلمات کلیدی با قوی ترین همبستگی با پرس و جو، درخواست شما را درک کند.
- سیستم های توصیه: با پایگاه داده های برداری بسیار کارآمد در ذخیره و بازیابی داده ها در ترکیب با یک مدل زبان و حافظه بزرگ، یک سیستم هوش مصنوعی ممکن است چیزهایی را که فرد دوست دارد در طول زمان یاد بگیرد. سپس این می تواند به طور خودکار توسط یک برنامه درخواست شود تا موارد مختلفی را که ممکن است به یک شخص علاقه مند باشد توصیه کند.
- تجزیه و تحلیل تصویر و ویدئو: با مدلهای جاسازی ویدئو و تصویر، مدلهای هوش مصنوعی را میتوان برای کار با تصاویر برای یافتن مواردی که شبیه به جستجو هستند، به خوبی تنظیم کرد. این در حال حاضر در بسیاری از اپلیکیشن ها و وب سایت های خرید آنلاین اجرا می شود.
- تشخیص ناهنجاری: با ثبت اقدامات بهعنوان جاسازیها، یک مدل هوش مصنوعی میتواند با شناسایی ناهنجاریها و نقاط دورافتاده خاص بر اساس هنجار، جهان را ایمنتر کند. تشخیص ناهنجاری هوش مصنوعی اکنون یک ابزار محبوب برای تشخیص تقلب، نظارت بر سیستم و نفوذ به شبکه است.
یک پایگاه داده برداری چگونه کار می کند
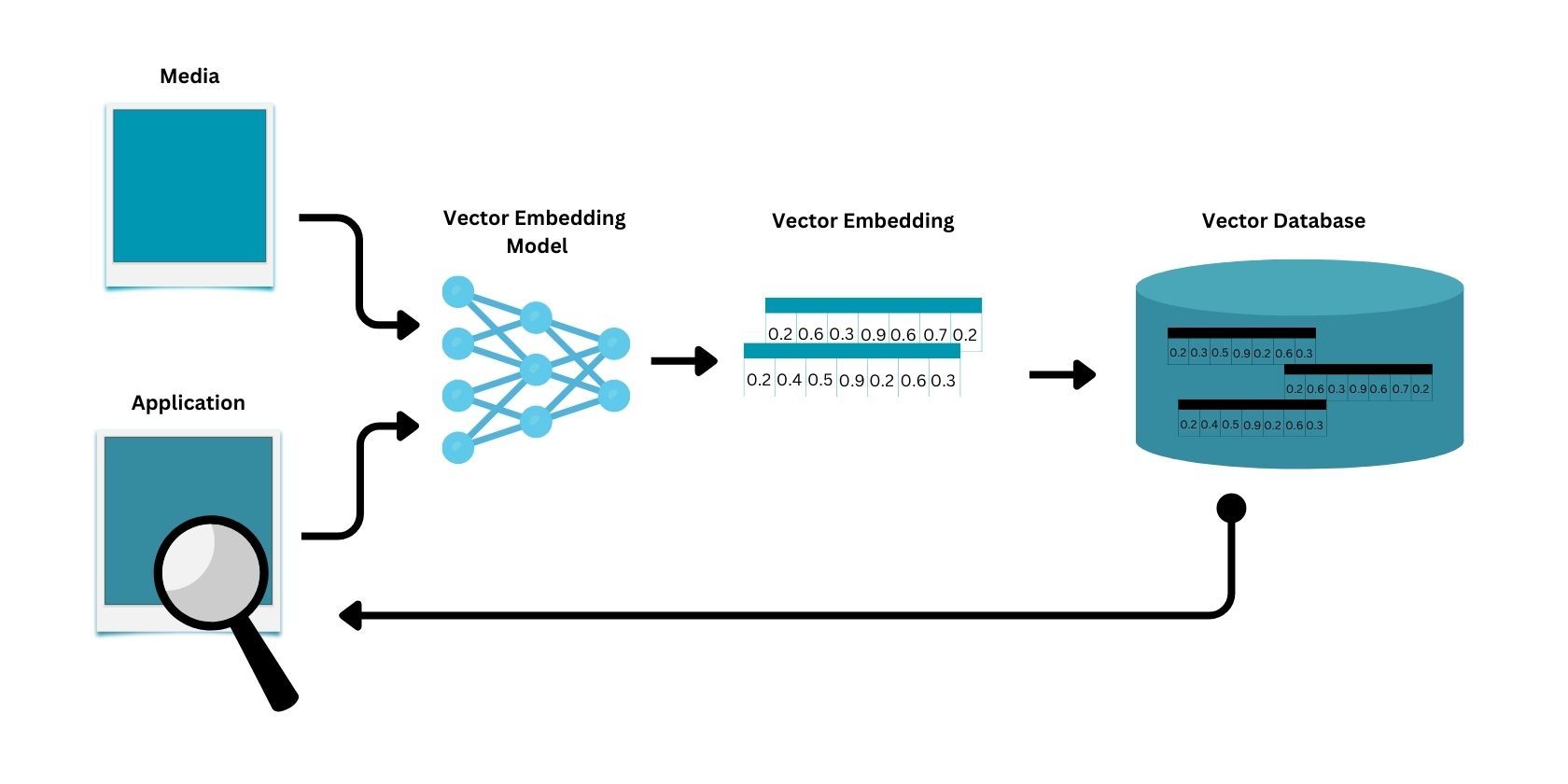
از تولید جاسازیهای برداری گرفته تا جستجوی دادهها از یک پایگاه داده برداری، دادههای شما تحت یک فرآیند سه مرحلهای قرار میگیرند:
- ایجاد جاسازی های برداری: بر اساس نوع داده ها، از مدل تعبیه برداری برداری برای تولید جاسازی های برداری برای نمایه سازی استفاده می شود. این مدلهای جاسازی، کلمات، تصاویر، ویدئوها و صدا را به اعداد/جاسازی تبدیل میکنند.
- نمایه سازی: پس از ایجاد جاسازی های برداری، اکنون می توان آنها را در یک پایگاه داده برداری مانند Pinecone، Milvus و Chroma ذخیره کرد. این پایگاههای داده برداری از الگوریتمهای مختلفی مانند کوانتیزهسازی محصول (PQ) و هشسازی حساس به محلی (LSH) برای فهرستبندی هر جاسازی برای ذخیرهسازی و بازیابی سریع و کارآمد دادهها استفاده میکنند.
- Querying: هنگامی که یک برنامه یک پرس و جو صادر می کند، پرس و جو باید ابتدا از طریق همان مدل جاسازی برداری که برای تولید داده های ذخیره شده در پایگاه داده برداری استفاده می شود، عبور کند. پرس و جو بردار ایجاد شده سپس در پایگاه داده برداری قرار می گیرد، جایی که نزدیک ترین بردار به عنوان مناسب ترین پاسخ به پرس و جو بازیابی می شود.
پایگاه های داده برداری محبوب
با گسترش مدلهای از پیش آموزشدیده در دسترس عموم، پایگاههای اطلاعاتی برداری به سرعت محبوبیت یافتند زیرا قابلیتها و میزان تنظیم دقیق این مدلها را گسترش دادند. و با چنین تقاضای زیاد برای پایگاه های داده برداری، بسیاری از شرکت ها خدمات پایگاه داده برداری خود را راه اندازی کرده اند. در اینجا برخی از محبوب ترین آنها وجود دارد:
- Pinecone: یک پایگاه داده برداری بومی ابری که برای جستجوی سریع تشابه طراحی شده است. دارای مقیاس پذیری بالا، تجزیه و تحلیل و بینش در زمان واقعی است که برای سیستم های توصیه و جستجوی تصویر عالی است.
- Milvus: یک پلت فرم وکتور منبع باز که با در نظر گرفتن جستجوی شباهت و برنامه های هوش مصنوعی ساخته شده است. قابلیت نمایه سازی و جستجوی سریع و کارآمد را برای بردارهای با ابعاد بالا فراهم می کند. علاوه بر این، Milvus از چندین الگوریتم نمایه سازی پشتیبانی می کند و SDK هایی را برای زبان های برنامه نویسی مختلف ارائه می دهد.
- Redis: یک پایگاه داده برداری با کارایی بالا که قادر به پشتیبانی از برنامه های کاربردی بلادرنگ، مدیریت جلسه و وب سایت های پربازدید است. Redis اغلب برای تجزیه و تحلیل بلادرنگ، جستجوی شباهت و سیستم های توصیه استفاده می شود.
- Weaviate: کشف طرحواره، بهروزرسانیهای همزمان، جستجوی معنایی و متنسازی دادهها را ارائه میدهد. با این ویژگی ها، Weaviate اغلب برای ایجاد سیستم های تجربه شخصی برای برنامه ها استفاده می شود.
آینده پایگاه های داده برداری
با رشد مداوم انواع دادههای با ابعاد بالا برای تصاویر، ویدئوها و متن، پایگاههای داده برداری نقش مهمی در بهبود و گسترش قابلیتهای مدلهای فعلی هوش مصنوعی ایفا خواهند کرد. از طریق توسعه مداوم با پایگاههای اطلاعاتی برداری، میتوان انتظار خدمات بهتری را در زمینههای مراقبتهای بهداشتی، مالی، تجارت الکترونیک و امنیت سایبری داشت.
اگر می خواهید یک پایگاه داده برداری را برای خود تجربه کرده و امتحان کنید، می توانید Auto-GPT را نصب کرده و یک پایگاه داده برداری مانند Pinecone را پیاده سازی کنید. البته، برای استفاده از خدمات آنها به یک کلید API نیاز دارید.