اکسل تقریباً در مورد همه چیز فرمول هایی دارد – برای یافتن داده ها ، اگر برای منطق ، و SUMIF برای کل مشروط. اما اگر تا به حال نیاز به استخراج الگوهای خاص از متن ، تأیید فرمت ها یا دستکاری رشته ها به روش های پیچیده داشته باشید ، احتمالاً به دیوار برخورد کرده اید. اینجاست که Regex وارد می شود.
اکسل تقریباً در مورد همه چیز فرمول هایی دارد – برای یافتن داده ها ، اگر برای منطق ، و SUMIF برای کل مشروط. اما اگر تا به حال نیاز به استخراج الگوهای خاص از متن ، تأیید فرمت ها یا دستکاری رشته ها به روش های پیچیده داشته باشید ، احتمالاً به دیوار برخورد کرده اید. اینجاست که Regex وارد می شود.
این می تواند مطابق با الگوی و دستکاری متن با دقت باشد. اما اگر آن را با عملکرد اسکن جفت کنید ، می توانید مشکلاتی را حل کنید که در غیر این صورت به چندین ستون یاور یا فرمول های تو در تو نیاز دارند. بنابراین ، اگر با داده های کثیف کار می کنید یا نیاز به اطلاعات خاص از رشته های متنی دارید ، این توابع ارزش آشنایی با آن را دارند.
ابتدا بیایید عملکرد Regex را درک کنیم
این تطابق الگوی است که پس از امتحان کردن منطقی است
Regex (کوتاه برای عبارات منظم) یک زبان تطبیق الگوی است که برای یافتن ، استخراج یا جایگزینی متن بر اساس قوانین خاص استفاده می شود. به جای جستجوی متن دقیق مانند “اپل” ، می توانید الگوهای را جستجو کنید – مانند “هر کلمه ای که از (الف) شروع می شود و با (ه)” یا “تمام آدرس های ایمیل در یک سلول شروع می شود”.
Regex یک نسخه دقیق تر از عملکرد Find Excel است که برای جستجوی اساسی کار می کند. با این حال ، Regex سناریوهای پیچیده تری را کنترل می کند. به عنوان مثال ، اگر شما نیاز دارید شماره تلفن را از متن کثیف بکشید ، یا باید همه چیز را بین پرانتز استخراج کنید یا فرمت های ایمیل را تأیید کنید ، پس از آن استفاده می کنید.
اگر در سایر زبان ها یا ابزارهای برنامه نویسی با الگوی تطبیق کار کرده اید ، عملکرد Regex اکسل به طور مشابه کار می کند. آنها متن را برای الگویی که شما تعریف می کنید اسکن می کنند ، سپس بر اساس آنچه پیدا می کنند ، اقدامات را انجام می دهند. این الگوهای خود از شخصیت های خاص و نحو استفاده می کنند-مانند \ d برای رقم یا [A-Z] برای حروف بزرگ-که در ابتدا می توانند رمزنگاری به نظر برسند اما با تمرین بصری می شوند.
اکسل دارای سه عملکرد Regex است که می توانید از آنها استفاده کنید
آنها کارهای مختلف را به خوبی انجام می دهند
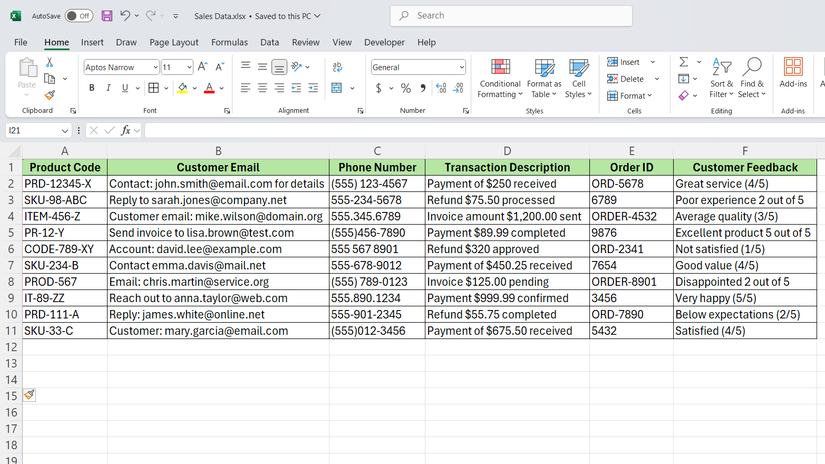
اکسل سه عملکرد Regex را در سال 2024 انجام داد: Regextest ، RegexExtract و RegexReplace. هر یک کار متفاوت را انجام می دهد ، و درک اینکه چه زمانی استفاده می کند که یکی از آنها تفاوت ایجاد می کند.
دوباره
این بررسی می کند که آیا الگویی در متن وجود دارد و درست یا نادرست برمی گردد. نحو این است:
= regextest (متن ، الگوی ، [حالت])
- متن: سلول یا رشته ای که می خواهید بررسی کنید.
- الگوی: الگوی Regex برای جستجوی.
- حالت (اختیاری): حساسیت مورد را کنترل می کند. از “I” برای تطبیق حساس به مورد استفاده کنید.
بگویید شما یک ستون از کدهای محصول در صفحه گسترده داده های فروش دارید و می خواهید ورودی هایی را که حداقل سه رقم متوالی دارند ، پرچم گذاری کنید. می توانید استفاده کنید:
= regextest (a2 ، “\ d {3}”)
اگر سلول A2 حاوی “PRD-12345-X” باشد ، عملکرد در ستون B درست باز می گردد زیرا سه رقم در یک ردیف پیدا کرده است.
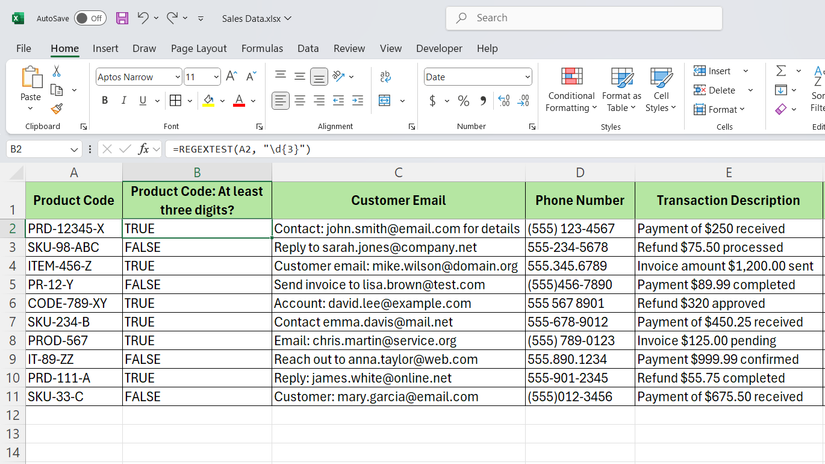
regexextract
این متن خاص را از یک رشته بر اساس یک الگوی بیرون می کشد. نحو این است:
= regexextract (متن ، الگوی ، [حالت] ، [نمونه])
- متن: متن منبع.
- الگوی: الگوی Regex که تعریف می کند چه چیزی را استخراج می کند.
- حالت (اختیاری): کنترل حساسیت مورد (“من” برای غیر حساس).
- نمونه (اختیاری): در صورت وجود چندین نفر (1 برای اول ، 2 برای دوم و غیره) کدام یک را برگردانید.
در داده های فروش ، ستون C حاوی ایمیل های مشتری است که با متن دیگر مخلوط شده است. برای استخراج فقط ایمیل ، ما استفاده خواهیم کرد:
= regexextract (b2 ، “[a-za-z0-9 ._ ٪+-]+@[a-za-z0-9 .-]+\. [a-za-z] {2 ،}”)
این الگوی فرمت های ایمیل استاندارد را مشخص می کند و آنها را به صورت تمیز در ستون D بیرون می کشد.
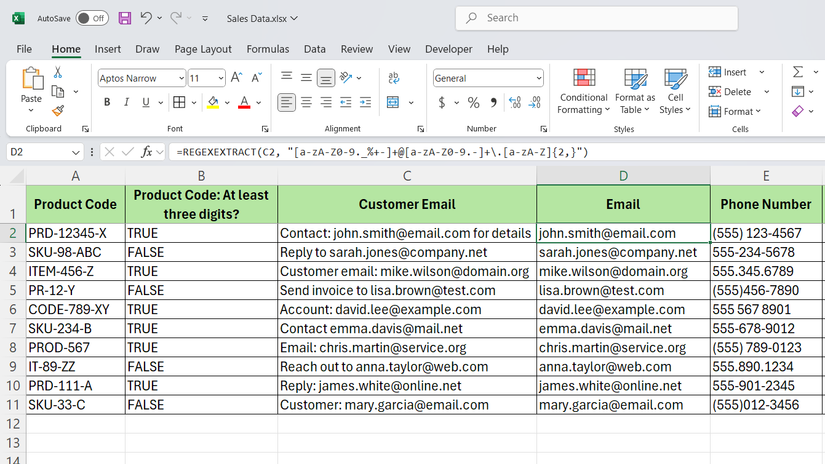
regexreplace
این متن را با یک الگوی با چیز دیگری مطابقت می دهد. نحو این است:
= RegexReplace (متن ، الگوی ، جایگزینی ، [حالت] ، [نمونه])
- متن: متن اصلی.
- الگوی: چه چیزی را پیدا کنیم.
- جایگزینی: چه چیزی را جایگزین آن کنید.
- حالت (اختیاری): حساسیت مورد.
- نمونه (اختیاری): کدام اتفاق برای جایگزینی (خالی برای جایگزینی همه).
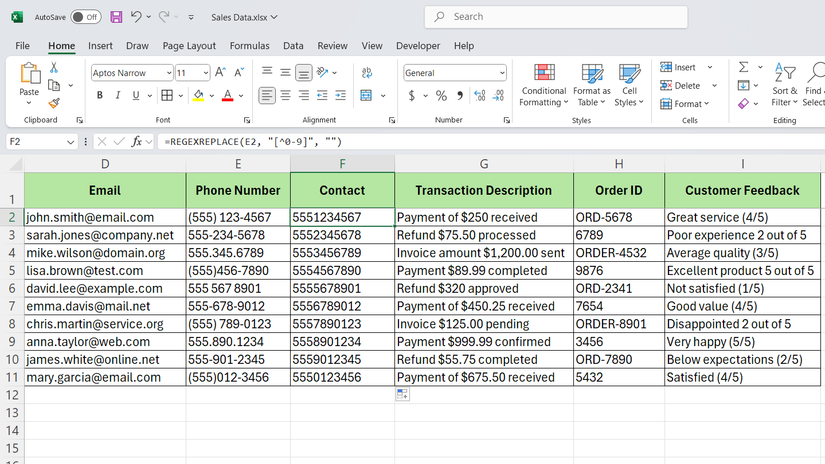
اگر ستون E در قالب های مختلف دارای شماره تلفن در قالب های مختلف باشد ، برخی از آنها با پرانتز – می توانید با استفاده از فرمول زیر ، آنها را استاندارد کنید تا همه چیز را به جز رقم انجام دهید:
= RegexReplace (C2 ، “[^0-9]” ، “”)
این الگوی [^0-9] به معنای “هر چیزی است که یک عدد نیست” است و جایگزین کردن آن با یک رشته خالی فقط رقم ها را ترک می کند.
این سه کارکرد بیشتر نیازهای دستکاری متن را پوشش می دهد. با این حال ، شما می توانید آنها را با عملکرد اسکن ترکیب کنید تا انعطاف پذیری بیشتری کسب کنید ، به خصوص برای پردازش داده ها در چندین ردیف یا استخراج الگوهای تکراری.
عملکرد اسکن باعث می شود Regex حتی بهتر شود
من هر دو را برای حل مشکلات پیچیده ترکیب می کنم
فرآیندهای اسکن آرایه ها به صورت ردیف ردیف و نتایج تجمعی را برمی گرداند. این یک محدوده کامل را طی می کند و ضمن پیگیری آنچه در گذشته انجام شده است ، بر خلاف توابع استاندارد که روی سلولهای منفرد کار می کنند ، یک تابع را برای هر مقدار استفاده می کند.
از نحو زیر استفاده می کند:
= اسکن ([اولیه_Value] ، آرایه ، لامبدا)
بیایید پارامترها را تجزیه کنیم:
- اولیه_Value (اختیاری): برای انتخاب نقطه شروع برای محاسبه خود. در صورت حذف ، اسکن از اولین عنصر آرایه به عنوان مقدار باتری اولیه استفاده می کند ، بنابراین عملیات عملکرد Lambda از آن عنصر شروع می شود.
- آرایه: دامنه سلولها برای پردازش.
- Lambda: یک تابع سفارشی که مشخص می کند با هر مقدار چه کاری انجام می شود. Lambda به شما امکان می دهد فرمول هایی مانند یک انسان بنویسید و دو استدلال می گیرد – نتیجه انباشته شده و مقدار فعلی.
به تنهایی ، اسکن برای اجرای کل یا پردازش مشروط مفید است. اما هنگامی که با عملکرد REGEX جفت می شوید ، می توانید الگوهای کل ستون ها را استخراج کرده و داده های کثیف را در یک فرمول تمیز کنید.
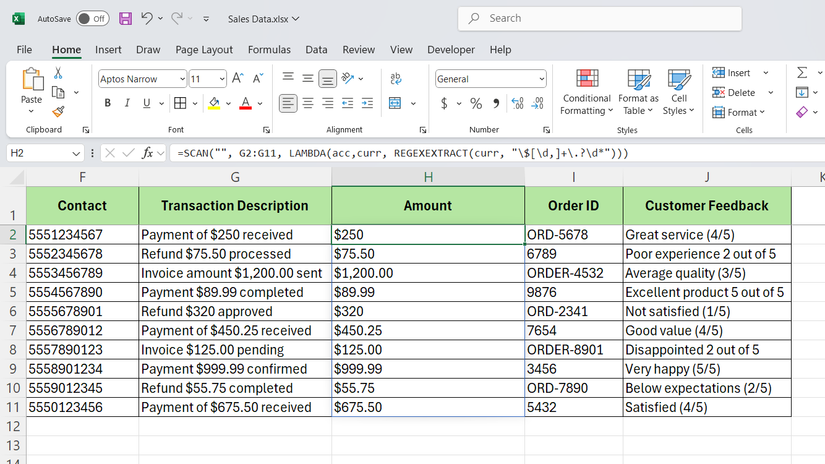
بیایید به یک مثال عملی نگاه کنیم. در صفحه گسترده داده های فروش ، ستون G شامل توضیحات معامله با مبالغی است که در داخل متن دفن شده است – مانند “پرداخت 250 دلار دریافت شده” یا “بازپرداخت 75.50 دلار پردازش شده”. شما فقط به مبلغ دلار نیاز دارید.
یک فرمول RegexExtract استاندارد برای یک سلول کار می کند:
= regexextract (d2 ، “\ $ \ d+\.؟ \ d*”)
اما برای پردازش کل ستون ، به طور معمول فرمول را صدها ردیف پایین می کشید. با اسکن ، همه آن را یکباره اداره می کنید ، فقط استفاده کنید:
= اسکن (“” ، G2: G11 ، Lambda (ACC ، Curr ، RegexExtract (curr ، “\ $ [\ d ،]+\.؟ \ d*”))
این فرمول از طریق سلول های G2 تا G11 حلقه می کند ، مبلغ دلار را از هر یک استخراج می کند و کل آرایه را برمی گرداند. مقدار انباشته (ACC) در اینجا لازم نیست زیرا ما فقط در حال استخراج هستیم ، اما اسکن هنوز هم در ساختار لامبدا به آن نیاز دارد.
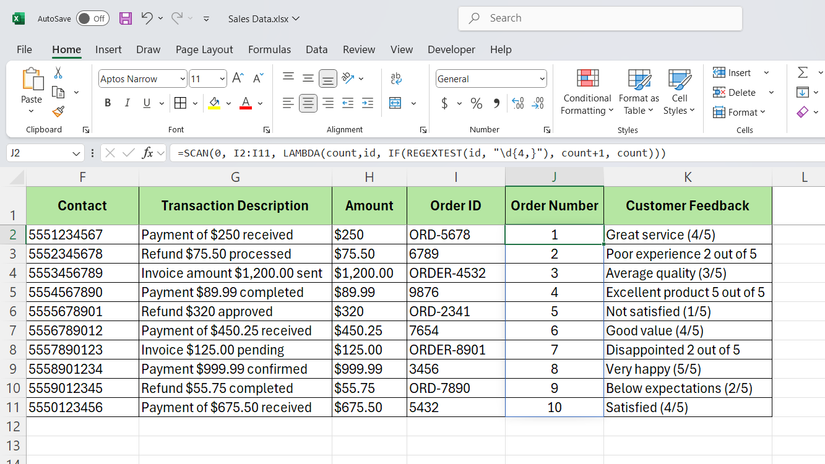
هنگامی که شما نیاز به ایجاد نتایج قبلی دارید ، مفید است. بگویید ستون اول ، شناسه های سفارش را متناقض می کند – بعضی از آنها پیشوندهایی دارند ، برخی این کار را نمی کنند. اگر می خواهید بخش عددی را استخراج کنید و تعداد شناسه های معتبر را در حال اجرا ایجاد کنید ، از آنها استفاده می کنید:
= اسکن (0 ، E2: E100 ، Lambda (تعداد ، شناسه ، اگر (regextest (id ، “\ d {4 ،}”) ، تعداد+1 ، تعداد)))
فرمول فوق هر سلول را برای حداقل چهار رقم متوالی با استفاده از عملکرد Regextest بررسی می کند. در صورت یافتن ، پیشخوان را افزایش می دهد. در غیر این صورت ، تعداد قبلی را در ستون J. حفظ می کند. نتیجه ستونی است که هنگام حرکت در لیست ، شناسه های معتبر تجمعی را نشان می دهد.
اسکن همچنین عملکردهای چند مرحله ای را در یک فرمول واحد انجام می دهد. اگر نیاز به استخراج ، اعتبار و تغییر متن به یکباره دارید ، لانه کردن عملکرد Regex در عملکرد اسکن این کار را بدون نیاز به ستون های یاور انجام می دهد. این به ویژه هنگام کار با مجموعه داده های بزرگ مفید است ، جایی که اضافه کردن ستون های اضافی می تواند کارها را کاهش دهد.
چه موقع از این توابع به جای فرمول های استاندارد استفاده کنید
Regex و Scan جایگزینی برای VLookup یا اگر هستند ، اما این ابزاری برای زمانی است که الگوهای متن بیشتر از مسابقات دقیق اهمیت دارند. اگر در حال تمیز کردن داده های وارداتی یا استخراج قطعات خاص از متن بدون ساختار هستید ، آنها در مقایسه با ویرایش های دستی یا توابع متن تو در تو ، وقت شما را صرفه جویی می کنند.
این نحو ممکن است در ابتدا مرعوب کننده به نظر برسد ، اما هنگامی که چند الگوی مانند اعتبار ایمیل ، استخراج شماره تلفن و نام های تقسیم شده را میخکوب کردید ، می توانید از آنها در پروژه ها استفاده مجدد کنید. در حالت ایده آل ، شما باید با Regextest شروع کنید تا الگوهای خود را بررسی کنید ، سپس در صورت نیاز به متن واقعی ، به RegexExtract بروید. در صورت نیاز به پردازش کل ستون ها و نیاز به اجرای نتایج ، اسکن را اضافه کنید.