خراش دادن HTML می تواند مشکل باشد، بنابراین مطمئن شوید که این فرآیند را با کمی تمرین پایتون درک کرده اید.
توییتر یکی از تاثیرگذارترین شبکه های اجتماعی است که تاکنون وجود داشته است. میلیون ها نفر از جمله سیاستمداران برجسته، افراد مشهور و مدیران عامل هر روز از این پلت فرم برای به اشتراک گذاشتن افکار خود استفاده می کنند.
برگه ترند یکی از بهترین مکان ها برای اطلاع از اخبار و احساسات رسانه های اجتماعی در زمان واقعی است. میتوانید از این دادهها برای برنامهریزی تبلیغات برند، اجرای کمپینها و افزایش فروش به صورت چند برابری آنالیز و استفاده کنید. اما چگونه می توانید ده هشتگ پرطرفدار در توییتر را به دست آورید؟
فرآیند ساخت الگوریتم
اولین قدم برای ساختن هر برنامه ای، یادداشت و درک مراحل مورد نیاز برای ساخت اسکریپر توییتر است. آن ها هستند:
- گوگل کروم را باز کنید.
- از صفحه پرطرفدار توییتر دیدن کنید.
- هشتگ ها و لینک صفحه مربوطه آنها را جمع آوری کنید.
- داده ها را در یک صفحه گسترده ذخیره کنید.
این به عنوان الگوریتم بیان مسئله عمل می کند.
آشنایی با صفحه وب توییتر
قبل از اینکه بتوانید آن را استخراج کنید، باید بدانید که چگونه یک صفحه وب داده های خود را علامت گذاری می کند. اگر درک خوبی از مبانی HTML و CSS داشته باشید بسیار کمک می کند.
این مراحل را دنبال کنید تا بفهمید توییتر چگونه یک هشتگ پرطرفدار و URL آن را نشان می دهد:
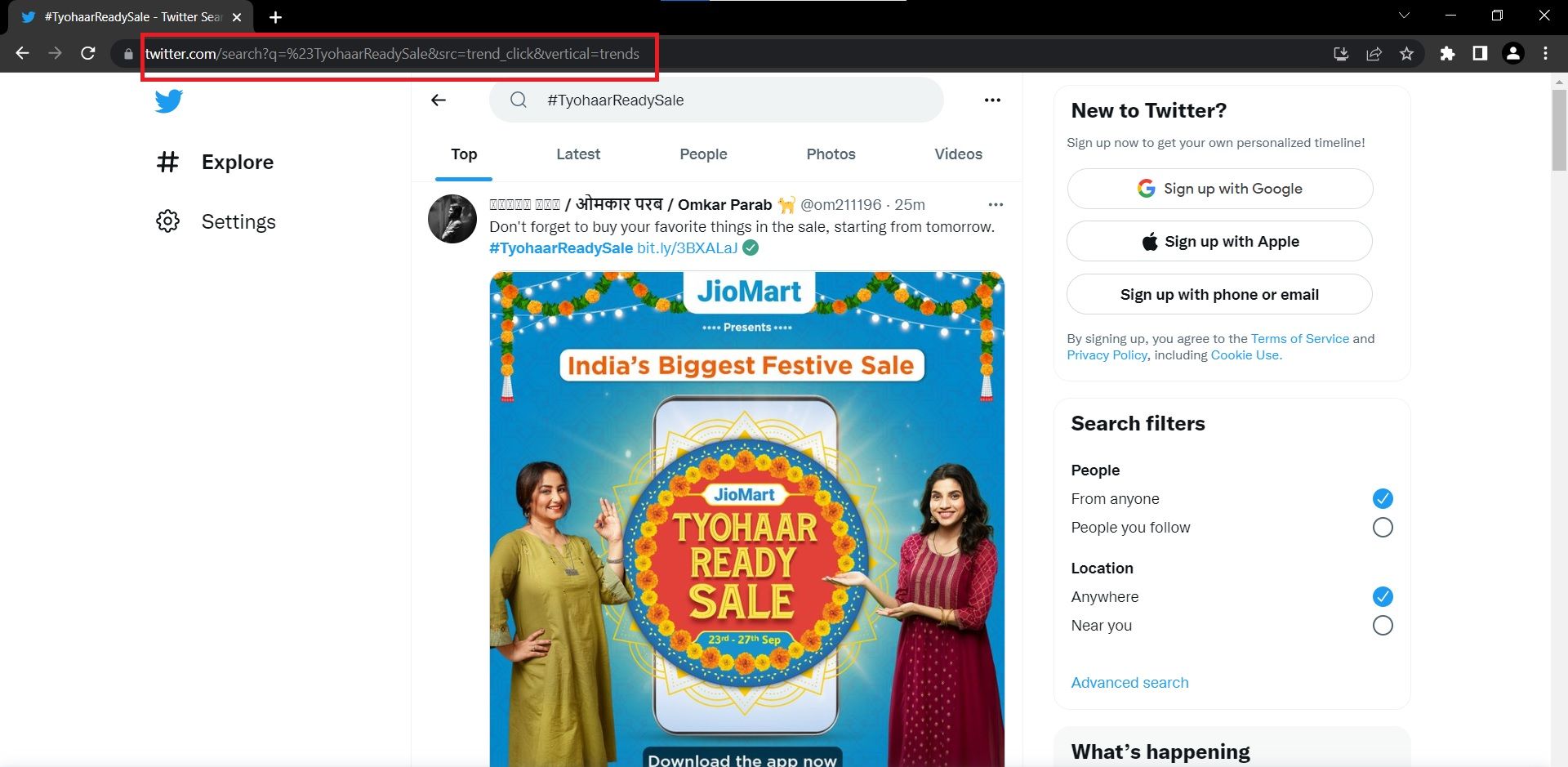
- از صفحه پرطرفدار توییتر دیدن کنید. همچنین می توانید برای مشاهده آن به Twitter.com → Explore → Trending بروید.
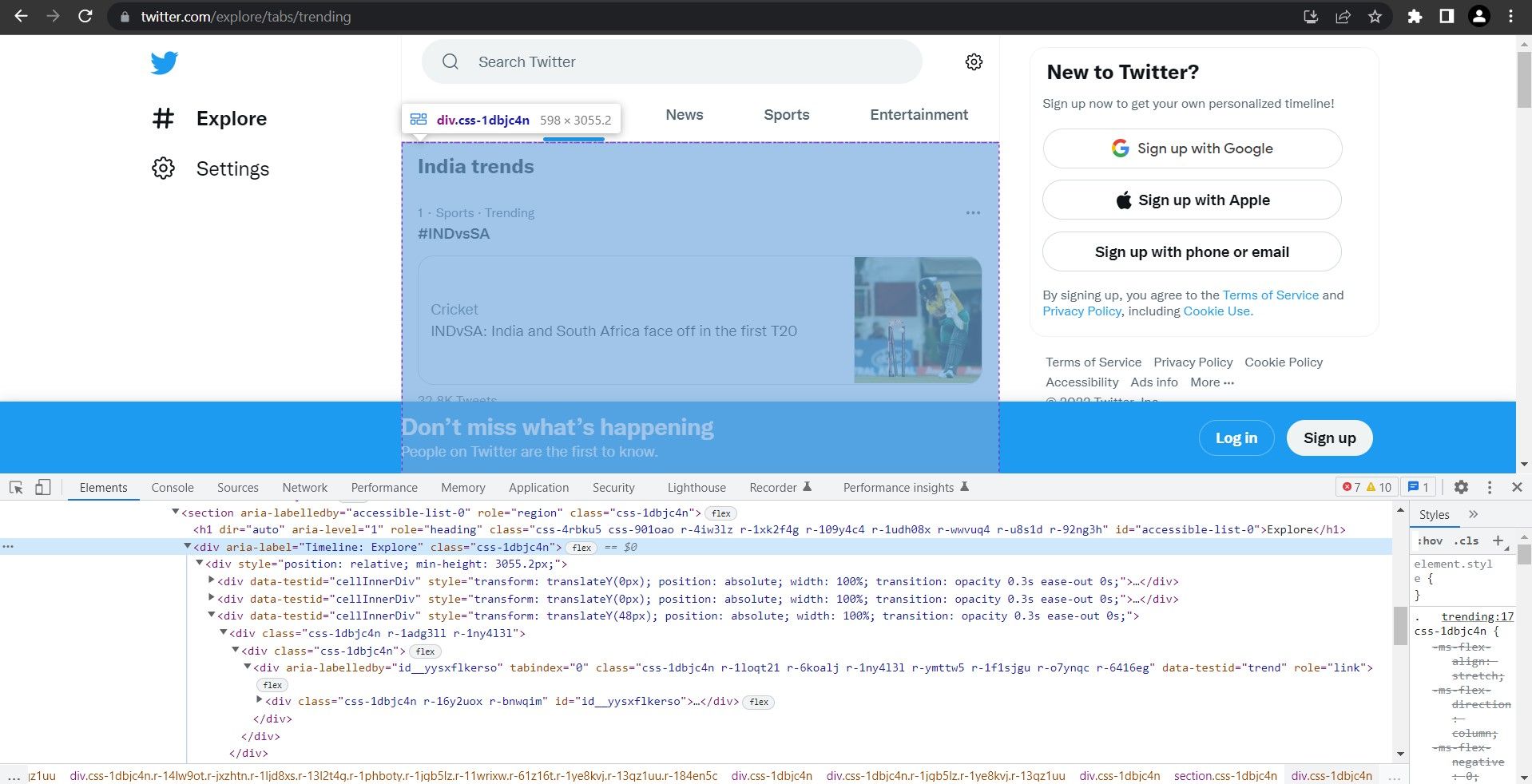
- ستون اصلی را با استفاده از Chrome Dev Tools بازرسی کنید. به منو (3 نقطه)> ابزارهای بیشتر > ابزارهای برنامه نویس بروید و ابزار انتخابگر عنصر را روی ناحیه پرطرفدار نگه دارید.
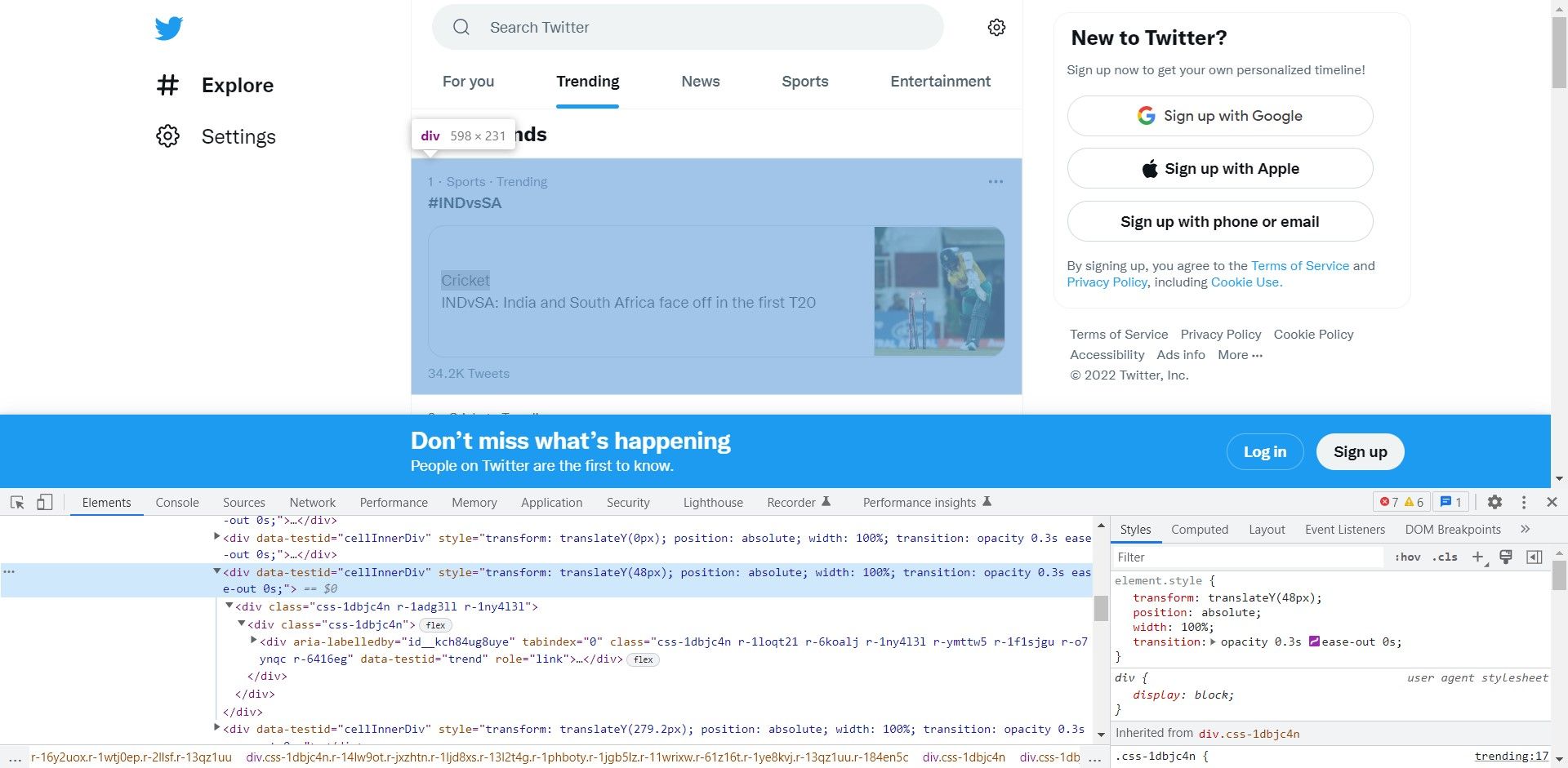
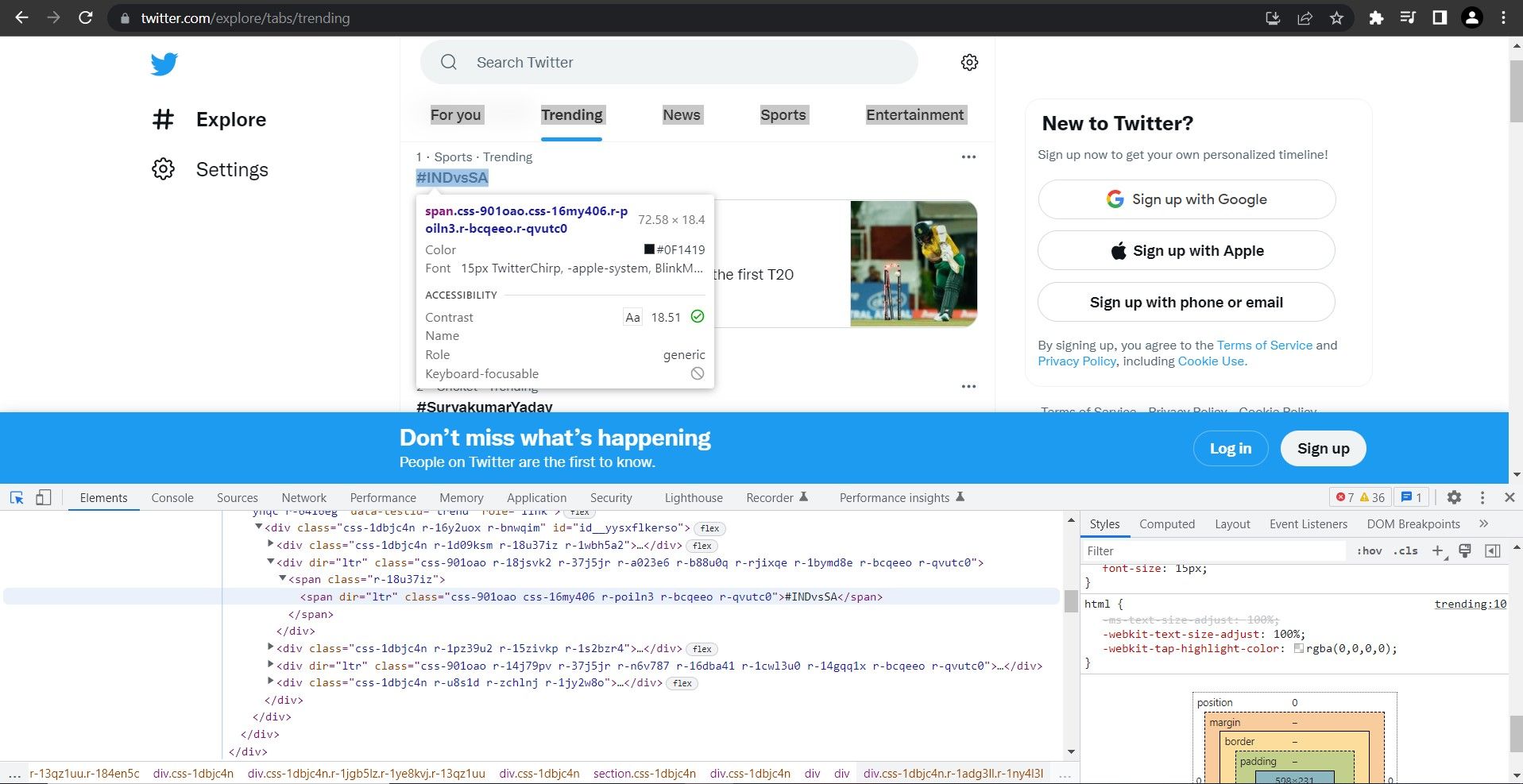
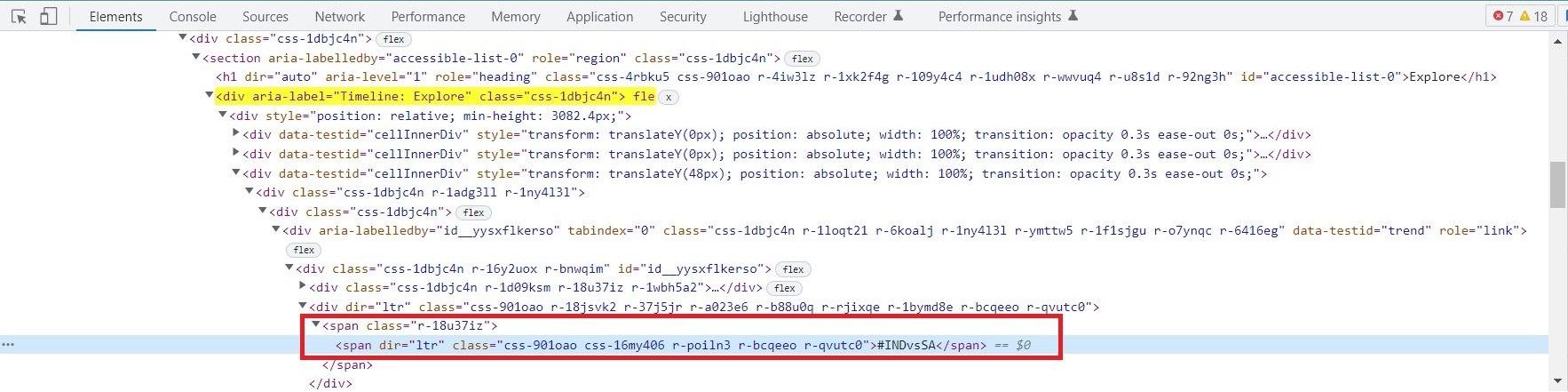
- Trending Timeline یک div با ویژگی aria-label است که مقدار آن “Timeline: Explore” است. برای درک بهتر ساختار صفحه، ماوس را روی نشانه گذاری در پانل Elements نگه دارید. div دیگری هشتگ/موضوع پرطرفدار را ذخیره می کند. از این div به عنوان شمارنده استفاده کنید و روی همه div های صفحه حاوی موضوع/هشتگ پرطرفدار تکرار کنید. محتوا در یک بازه یا چند عنصر span ذخیره می شود. برگه باز را مشاهده کنید و سلسله مراتب را یادداشت کنید. شما می توانید از این برای ساخت یک عبارت XPath استفاده کنید. عبارت XPath برای این عنصر خاص این است:’//div[@aria-label=”Timeline: Explore”]/div[1]/div[3]/div[1]/div[1]/div[1] /div[1]/div[2]/span[1]’ تکرار و هدف قرار دادن div[3]، div[4]، div[5] و غیره. برای ده هشتگ برتر، شمارنده از 3 تا 13 اجرا می شود. XPath تعمیم یافته تبدیل می شود:://div[@aria-label=”Timeline: Explore”]/div[1]/div[{i}]/div[1 ]/div[1]/div[1]/div[1]/div[2]/span[1]’
- روی هر هشتگ کلیک کنید تا آدرس صفحات آن را بفهمید. اگر URL ها را با هم مقایسه کنید، باید متوجه شوید که فقط پارامتر query برای مطابقت با نام هشتگ تغییر می کند. شما می توانید از این بینش برای ساختن URL ها بدون استخراج واقعی آنها استفاده کنید.
'//div[@aria-label="Timeline: Explore"]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]'
//div[@aria-label="Timeline: Explore"]/div[1]/div[{i}]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]'
درک و نصب ماژول ها و ابزارهای مورد نیاز
این پروژه از ماژول ها و ابزار پایتون زیر استفاده می کند:
1. ماژول پانداها
شما می توانید از کلاس Pandas DataFrame برای ذخیره هشتگ ها و لینک های مربوط به آنها در قالب جدولی استفاده کنید. این برای افزودن این محتویات به یک فایل CSV که میتوانید به صورت خارجی به اشتراک بگذارید، مفید خواهد بود.
2. ماژول زمان
از ماژول Time برای اضافه کردن تاخیر به برنامه پایتون استفاده کنید تا محتویات صفحه به طور کامل بارگذاری شوند. این مثال از 15 ثانیه تاخیر استفاده می کند، اما شما می توانید آزمایش کنید و یک تاخیر مناسب برای شرایط خود انتخاب کنید.
3. ماژول سلنیوم
سلنیوم می تواند فرآیند تعامل با وب را خودکار کند. میتوانید از آن برای کنترل نمونهای از یک مرورگر وب، باز کردن صفحه پرطرفدار و اسکرول کردن آن به پایین استفاده کنید. برای نصب سلنیوم در محیط پایتون، ترمینال خود را باز کرده و سلنیوم نصب پیپ را اجرا کنید.
4. درایور وب
از یک درایور وب در ترکیب با سلنیوم برای تعامل با مرورگر استفاده کنید. بر اساس مرورگری که می خواهید خودکار کنید، درایورهای وب متفاوتی وجود دارد. برای این ساخت، از مرورگر محبوب گوگل کروم استفاده کنید. برای نصب درایور وب برای کروم:
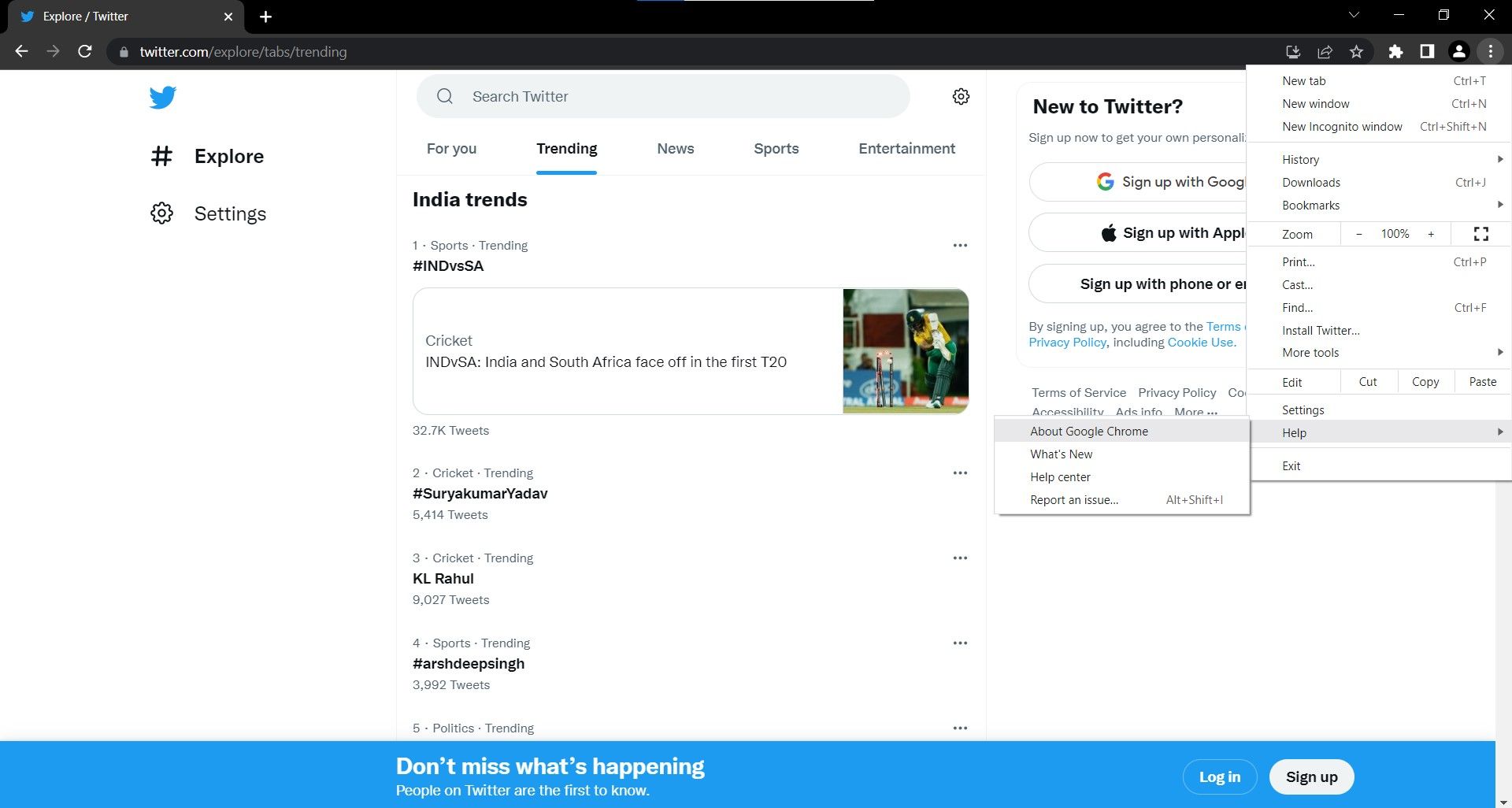
- با مراجعه به منو (3 نقطه) > راهنما> درباره Google Chrome، نسخه مرورگر مورد استفاده خود را بررسی کنید.
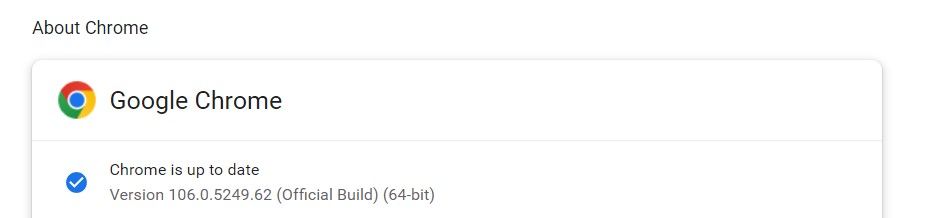
- به نسخه مرورگر توجه کنید. در این مورد، 106.0.5249.62 است.
- به ترمینال خود بروید و pip install را تایپ کنید chromedriver-binary==version_number:pip install chromedriver-binary==106.0.5249.62 اگر نسخه مشابهی وجود نداشته باشد، pip لیستی از موارد موجود را به شما نشان می دهد. نزدیک ترین مورد به نسخه کروم خود را انتخاب کنید.
pip install chromedriver-binary==106.0.5249.62
نحوه ساخت Scraper توییتر
این مراحل را دنبال کنید تا برنامه خود را بسازید و هشتگ های پرطرفدار را در زمان واقعی دریافت کنید. شما می توانید کد منبع کامل را در این مخزن GitHub پیدا کنید.
- ماژولهای مورد نیاز را در محیط پایتون وارد کنید.# وارد کردن ماژولهای مورد نیاز از واردات سلنیوم webdriverfrom selenium.webdriver.common.by وارد کردن Byimport chromedriver_binaryimport timeimport pandas به صورت pd
- یک شی برای مقداردهی اولیه ChromeDriver ایجاد کنید و مرورگر Google Chrome را با استفاده از تابع webdriver.Chrome() راه اندازی کنید.# مرورگر مرورگر google chrome = webdriver.Chrome() را باز کنید.
- صفحه ترند توییتر را با ارسال URL آن به تابع get() باز کنید.# صفحه ترند Twitter Browser.get را باز کنید (‘https://twitter.com/explore/tabs/trending’)
- یک تاخیر اعمال کنید تا محتوای صفحه به طور کامل بارگیری شود.# تاخیر برای محتوای صفحه loadingtime.sleep(15)
- یک لیست خالی برای ذخیره هشتگها ایجاد کنید و یک حلقه از 3 تا 13 را برای مطابقت با متغیر موجود در عبارت XPath از قبل اعلام کنید. برای i در محدوده (3،13):
# importing the required modules
from selenium import webdriver
from selenium.webdriver.common.by import By
import chromedriver_binary
import time
import pandas as pd
# open google chrome browser
browser = webdriver.Chrome()
# open the trending page of Twitter
browser.get('https://twitter.com/explore/tabs/trending')
# delay for page content loading
time.sleep(15)
# initialize list to store trending topics and hashtags
trending_topic_content=[]
# collect topics and hashtags on Twitter's trending page
for i in range(3,13):
- از تابع find_element() استفاده کنید و از انتخابگر XPath عبور دهید تا موضوعات و هشتگهای پرطرفدار در Twitter را دریافت کنید:xpath = f’//div[@aria-label=”Timeline: Explore”]/div[1]/div[{i }]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]’trending_topic = browser.find_element(By.XPATH, xpath)trending_topic_content.append(trending_topic .text)
- یک لیست خالی برای ذخیره همه URL ها ایجاد کنید و یک حلقه را اعلام کنید که در تمام هشتگ ها اجرا می شود.# URL ها را با استفاده از هشتگ ها ایجاد کنید collectedurls=[]for i در trending_topic_content: از عملگر slice استفاده کنید تا هشتگ را حذف کنید تا URL آن ایجاد شود و فاصله ها جایگزین شود. با رمزگذاری URL، %20. پیوندها را به list اضافه کنید.if i.startswith(“#”): i = i[1:] url=’https://twitter.com/search?q=%23′ + i + ‘&src=trend_click’ else: url = ‘https://twitter.com/search?q=’ + i + ‘&src=trend_click’url = url.replace(” “، “%20”)urls.append(url)
- یک دیکشنری جفت کلید-مقدار با کلیدها به عنوان هشتگ و مقادیر به عنوان URL آنها ایجاد کنید.# فرهنگ لغتی ایجاد کنید که دارای هشتگ و URLsdic={‘HashTag’:trending_topic_content,’URL’:urls} باشد.
- دیکشنری بدون ساختار را به یک DataFrame جدولی تبدیل کنید.# دیکشنری را به یک دیتافریم در pandasdf=pd.DataFrame(dic)print(df) تبدیل کنید.
- DataFrame را در یک فایل CSV که میتوانید در مایکروسافت اکسل مشاهده کنید یا بیشتر پردازش کنید، ذخیره کنید.
xpath = f'//div[@aria-label="Timeline: Explore"]/div[1]/div[{i}]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]'
trending_topic = browser.find_element(By.XPATH, xpath)
trending_topic_content.append(trending_topic.text)
# create URLs using the hashtags collected
urls=[]
for i in trending_topic_content:
if i.startswith("#"):
i = i[1:]
url='https://twitter.com/search?q=%23' + i + '&src=trend_click'
else:
url = 'https://twitter.com/search?q=' + i + '&src=trend_click'
url = url.replace(" ", "%20")
urls.append(url)
# create a dictionary that has both the hashtag and the URLs
dic={'HashTag':trending_topic_content,'URL':urls}
# convert the dictionary to a dataframe in pandas
df=pd.DataFrame(dic)
print(df)
# convert the dataframe into Comma Separated Value format with no serial numbers
df.to_csv("Twitter_HashTags.csv",index=False)
با استفاده از Web Scraping بینش های ارزشمندی به دست آورید
Web scraping روشی قدرتمند برای به دست آوردن داده های مورد نظر و تجزیه و تحلیل آن ها برای تصمیم گیری است. Beautiful Soup یک کتابخانه چشمگیر است که می توانید آن را نصب کرده و برای پاک کردن داده ها از هر فایل HTML یا XML با استفاده از Python استفاده کنید.
با این کار، می توانید اینترنت را خراش دهید تا عناوین اخبار، قیمت محصولات، امتیازات ورزشی، ارزش سهام و موارد دیگر را به دست آورید.